
Blueprint Deep Dive: Turn Documents into Podcasts Locally with Open-Source AI
Blueprints are customizable workflows that help developers build AI applications using open-source tools and models. In this blog, we’ll dive into our first Blueprint: document-to-podcast. We’ll explain how it works, our technical decisions, and how you can use and customize it yourself.


At Mozilla.ai we’re committed to helping developers adopt open-source AI tools and models with confidence. In our previous blog post, we introduced the concept of Blueprints – customizable workflows that help developers build AI applications using open-source tools and models. In this blog, we’ll dive into our first Blueprint: document-to-podcast. We’ll explain how it works, our technical decisions, and how you can use and customize it yourself. This Blueprint is showcased on the Mozilla.ai Blueprints Hub (currently in Beta), where you can find tutorials, related content, and discover other Blueprints.
Why Document-to-Podcast?
Turning documents into podcasts has been a hot topic recently, with tools like Google’s NotebookLM driving much of the interest. However, many of these tools are closed-source or rely on large proprietary models and are designed more for consumers rather than developers who want to build their own applications. For our Blueprint we decided to focus on:
- Fully local setup: This Blueprint works standalone, without the use of any third-party APIs, offering privacy and control of your data.
- Low compute requirements: We’ve prioritized models that can run on most local set-ups and even run in GitHub Codespaces, so you can easily experiment without needing a high-end GPU or API key.
- Customization: The Blueprint is flexible, allowing you to modify configuration parameters or extend it with new components, and we show you how you can build a basic app using its components.
How does it work?
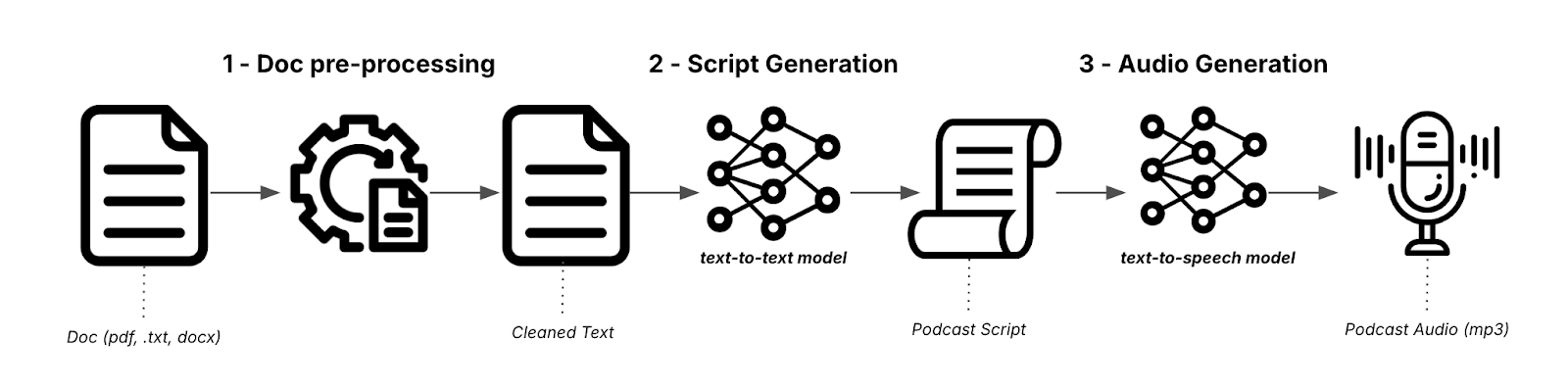
Transforming a document into an engaging podcast episode involves three main steps:
- 📄 Document pre-processing: Prepares the input document by extracting and cleaning the text.
- 📜 Podcast script generation: Uses an LLM to transform the cleaned text into a conversational podcast script.
- 🎙️ Audio generation: Converts the script into an engaging audio podcast with distinct speaker voices using a text-to-speech model.
Document pre-processing
In many LLM-based pipelines, it’s easy to overlook pre-processing, especially if you’re relying on very large context windows from a closed-model API. But for local, smaller models, it’s crucial to optimize what you pass in as input. Here’s what we do:
- File loading: Handled by data_loaders.py, this extracts readable text for different document formats (.html, .pdf, .txt, and .docx).
- Text cleaning: Handled by data_cleaners.py and using Python’s re library, this removes URLs, email addresses, and special characters for a clean, consistent input.
Here’s an example of pre-processing using the document-to-podcast API:
from document_to_podcast.preprocessing import DATA_CLEANERS, DATA_LOADERS
input_file = "example_data/introducing-mozilla-ai-investing-in-trustworthy-ai.html"
data_loader = DATA_LOADERS[".html"]
data_cleaner = DATA_CLEANERS[".html"]
raw_data = data_loader(input_file)
print(raw_data[:200])
"""
<!doctype html>
<html class="no-js" lang="en-US">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1">
<link rel="profile" href="https://gmpg.org/x
"""
clean_data = data_cleaner(raw_data)
print(clean_data[:200])
"""
Skip to content Mozilla Internet Culture Deep Dives Mozilla Explains Interviews Videos Privacy Security Products Firefox Pocket Mozilla VPN Mozilla News Internet Policy Leadership Mitchell Baker, CEO
"""
Tip: If you pass in too much “useless” text, you waste compute and risk hitting context window limits. Pre-processing ensures each token counts.
We started with this fairly standard pre-processing implementation, however, the community is also helping us explore ways of improving this step in the pipeline by using libraries like markitdown. Check out Issue #66 on GitHub to contribute or see how the community is tackling this.
Podcast script generation
In this step, the pre-processed text is transformed into a podcast transcript. Here’s how it works:
- Model loading
- We wanted this Blueprint to run locally on most set-ups, so we decided to use llama_cpp to load the models, as it supports CPU-friendly inference, making the Blueprint more accessible. More specifically, it executes inference in C/C++ and loads models in an optimized binary format called GGUF.
- Model_loader.py uses llama_cpp and can accept any GGUF-type model.
- As a default, we decided to use Qwen2.5-3B-Instruct, which showed good results in our tests.
- Text generation
- Text_to_text.py uses the loaded model, the input text (e.g. the document you’ve uploaded), and a user-defined system prompt to generate a podcast script.
- The main challenge here was composing a system prompt that ensured the script was well-structured for the audio generation step. We found that setting the response_format argument in the llama_cpp create_chat_completion function to a JSON object significantly improved the consistency of the generated script.
Here’s an example of script generation using the document-to-podcast API:
from document_to_podcast.inference.model_loaders import load_llama_cpp_model
from document_to_podcast.inference.text_to_text import text_to_text, text_to_text_stream
# Load the model
model = load_llama_cpp_model(
"Qwen/Qwen2.5-1.5B-Instruct-GGUF/qwen2.5-1.5b-instruct-q8_0.gguf"
)
# Define your input and system prompt
input_text = (
"Electric vehicles (EVs) have seen a significant rise in adoption over the past "
"decade, driven by advancements in battery technology, government incentives, "
"and growing consumer awareness of environmental issues."
)
system_prompt = (
"""
You are a podcast scriptwriter generating engaging and natural-sounding conversations in JSON format.
- Write dynamic, easy-to-follow dialogue.
- Include natural interruptions and interjections.
- Avoid repetitive phrasing between speakers.
- Format output as a JSON conversation.
Example:
{
"Speaker 1": "Welcome to our podcast! Today, we're exploring...",
"Speaker 2": "Hi! I'm excited to hear about this. Can you explain...",
}
"""
)
# Generate a podcast script from the input text
podcast_script = text_to_text(input_text, model, system_prompt)
print(podcast_script)
"""
{
"Speaker 1": "Welcome to our podcast! Today, we're exploring the rise of electric vehicles (EVs) and what's driving this significant increase in adoption over the past decade.",
"Speaker 2": "Absolutely, it's fascinating to see how the market has evolved and how consumers are becoming more environmentally conscious.",
"Speaker 1": "Absolutely! Let's dive into the key factors driving this growth.",
"Speaker 2": "Sure, here are a few key drivers: advancements in battery technology, government incentives, and growing consumer awareness of environmental issues.",
...
}
"""Tip: Changing the model you’re using may require adjusting your prompt, as different models can produce significantly different results from the same input prompt.
Audio Generation
In this step, the podcast transcript is converted into audio with multiple speakers. Converting the generated script into audio turned out to be more challenging than text generation. Unlike text generation, where open-source frameworks like llama_cpp or hugging-face-transformers make it easy to swap in different models, text-to-speech systems often have non-standardized setups and diverse dependencies.
We tried several TTS libraries, initially choosing Parler-tts, but then ultimately defaulting the Blueprint to use OuteTTS or Kokoro-82M, for their more consistent pronunciation of domain-specific words. Here’s how this step works in the Blueprint:
- Model loading: The model_loader.py script is responsible for loading the TTS models using the OuteTTS and Parler_tts libraries. The TTS model is loaded based on the model ID provided.
- Text-to-speech generation: The text_to_speech.py script uses the loaded TTS model to convert text into audio. The speaker profile parameter defines the voice characteristics (e.g., tone, speed, clarity) for each speaker. This is specific to each TTS library – OuteTTS models require one of the IDs specified here.
Here’s an example of audio generation using the document-to-podcast API:
import soundfile as sf
from document_to_podcast.inference.model_loaders import load_outetts_model
from document_to_podcast.inference.text_to_speech import text_to_speech
# Load the TTS model
model = load_outetts_model(
"OuteAI/OuteTTS-0.1-350M-GGUF/OuteTTS-0.1-350M-FP16.gguf"
)
# Generate the waveform
waveform = text_to_speech(
input_text="Welcome to our amazing podcast",
model=model,
voice_profile="male_1"
)
# Save the audio file
sf.write(
"podcast.wav",
waveform,
samplerate=model.audio_codec.sr
)Give it a try!
To get started, visit the document-to-podcast repo and check out our Guidance Docs for more detailed instructions. You can choose from four simple ways to start using this workflow:
- Remote Demo app (GitHub Codespaces): Launch the project directly in GitHub Codespases with no installation required and run the command for the demo in the terminal. Note that you will be uploading your input data into a short-lived VM from GitHub.
- Local Demo app: Install the project locally and run the command for the demo in a local terminal.
- Local CLI: In addition to the UI demo, there is the option to run it from the command line, with easier configuration of parameters, either by defining your own config.yaml file or by directly passing arguments in the CLI.
- Colab Notebook: If you prefer not to set up Codespaces or install locally, try the end-to-end workflow in a GPU-enabled Google Colab notebook here.
Customizing the Blueprint for your needs
The Document-to-Podcast Blueprint is built for flexibility, allowing you to adapt it to your specific needs. Here are some of the parameters you can customize in the config file to make it work for you:
- text_to_text_model: You can change the text-to-text model used for podcast script generation. Note: The model parameter must be in GGUF format.
- text_to_text_prompt: You can change the prompt used to generate the podcast script. The prompt helps to define the tone, structure, and instructions for generating the podcast script. This prompt is crucial for tailoring the conversation style to your project.
- text_to_speech_model: You can change the text-to-speech model used to generate the podcast audio. Performance can vary quite a lot from model to model. By default, the Blueprint works with OuteTTS models, for other models, you will need to install additional TTS libraries.
- speakers: Defines the podcast participants, including their names, roles, descriptions, and voice profiles. Customize this to create engaging personas and voices for your podcast. Note that voice profiles are specific to the text-to-speech model you use.
Changing these parameters can enable you to use the Blueprint for a broad range of applications. Here are a couple of examples of how they can be changed for different use-cases:
- Radio Drama Generator: An adaptation that generates radio dramas by customizing the Blueprint parameters.
- Readme-to-Podcast: An adaptation that transforms GitHub README files into podcast-style audio to help you understand how the repo works.
The Blueprint and its components are designed for flexibility, allowing you to extend them to expand their capabilities and scope. Here’s an example of extending the Blueprint to include additional TTS libraries (Parler-tts, suno-bark), enabling multi-language podcast generation: document-to-podcast-multi-language.
For more information on customization, check out the Customization Guide.
We believe for Blueprints to thrive, they will require diverse ideas and community contributions. We invite you to explore the issues page to find feature requests you can contribute to or share your own ideas by raising a new issue.
If you have an idea for a Blueprint that you think would be a great fit for the Blueprints Hub, feel free to reach out to me at stefan@mozilla.ai
Stay tuned for new Blueprints from Mozilla.ai and the community, covering different use cases and showcasing what’s possible with open-source tools and models, by also visiting the Blueprints Hub (currently in Beta).



