
Build Your Own Timeline Algorithm: A Blueprint
Timeline algorithms should be useful for people, not for companies. Their quality should not be evaluated in terms of how much time people spend on a platform, but rather in terms of how well they serve their users’ purposes.

Timeline algorithms should be useful for people, not for companies. Their quality should not be evaluated in terms of how much time people spend on a platform, but rather in terms of how well they serve their users’ purposes.
This is just the start of the description of BYOTA, presented at the Social Web track at FOSDEM 2025. What started as a personal project is now a Mozilla.ai Blueprint, introducing an approach to personal, local timeline algorithms that people can either run out-of-the-box or customize. The approach relies on a stack which makes use of Mastodon.py to get recent timeline data, llamafile to calculate text embeddings locally, and marimo to provide a UI that runs in one’s own browser. Using this stack, you will learn how to perform search, grouping, and recommendation of posts from the Fediverse without any of them leaving your computer.
Why?
Commercial platforms’ timeline algorithms (i.e. the algorithms that define which posts appear in your social media timeline and in which order) are all affected by one or more of the following problems: bias; lack of privacy, transparency, and user control; and reliance on ML algorithms, which are complex, computationally heavy and require to run in a centralized way.
In practice, though, you have to juggle with these problems only when your objective is to retain users. If the objective changes (e.g. serve people’s different purposes), one can immediately realize there is a solution to each of these problems, one that relies on open, small, interpretable models that can be run locally for ad-hoc tasks without requiring too much ML knowledge.
The above answers the question: “Why should people build/run their own timeline algorithms?”. Now you might be asking yourself: “Why a Blueprint?”. BYOTA is not an end-user application, but rather a playground for people to learn about timeline algorithms, a call to action for developers to experiment with and create new tools for open, federated social networks. And blueprints facilitate this, as they do not only provide code and structured documentation, but also serve as artifacts for communities to collaborate in a situated learning fashion.
How it works
BYOTA is built on this assumption: Do something useful while preserving user privacy and control, using open models and local-first technologies. While the concept sounds quite straightforward, developing something which is easy to use and customize, and at the same time computationally light and useful, is not as simple. Luckily, there are some great tools we can rely on for this:
- Mastodon.py (MIT License) is a python client library for Mastodon. You will use it to download new posts from your instance’s timelines.
- Llamafile (Apache 2.0 License) is a Mozilla tool that packages a language model in a single executable file that will run on most platforms. It is 100% local and has been optimized to run on slower hardware. We use it to run all-minilm, a tiny (50MB) sentence transformer model, specialized in calculating embeddings from text.
- Marimo (Apache 2.0 License) is a reactive notebook for Python, that is also sharable as an application. For instance, you can download BYOTA’s marimo notebook from its repo, install its python dependencies, and run it locally as any python notebook; but you can also deploy it as a WASM application and people will be able to run it in their browser with no need to install anything else.
Here is how these tools work together: The marimo notebook uses Mastodon.py to download posts from timelines, then it asks llamafile to generate a semantic embedding from the content of each post, finally it uses these embeddings to visualize, search, or re-rank all posts in a timeline.
Give it a try
There are a few different ways you can run BYOTA:
- Option-1: If you just want to try and see what it can do, then click here to play with its demo on HuggingFace Spaces. You will be asked for a password which, quite unsurprisingly, is
byota. - Option-2: If you want to run BYOTA locally and have Docker installed, you can run a container with the following command:
docker run -it -p 8080:8080 -p 2718:2718 mzdotai/byota:latest demo.py… and access the demo at http://localhost:2718 (same password to access).
- Option-3: To avoid hitting any Mastodon server from our open demo, in options 1 and 2, we have included some synthetic data to play with. If you want to run the code on your own data instead, follow the steps described in the blueprint’s documentation to register your own Mastodon app and start a marimo notebook that will use the app’s credentials to access your account. Note that, except for the connections to your Mastodon instance’s API, the rest of the code will run locally.
- Option-4: If you want to customize the code or any of the components (e.g. choose a different embedding model or server), you can deploy everything on your system by following these instructions.
What can I do with BYOTA?
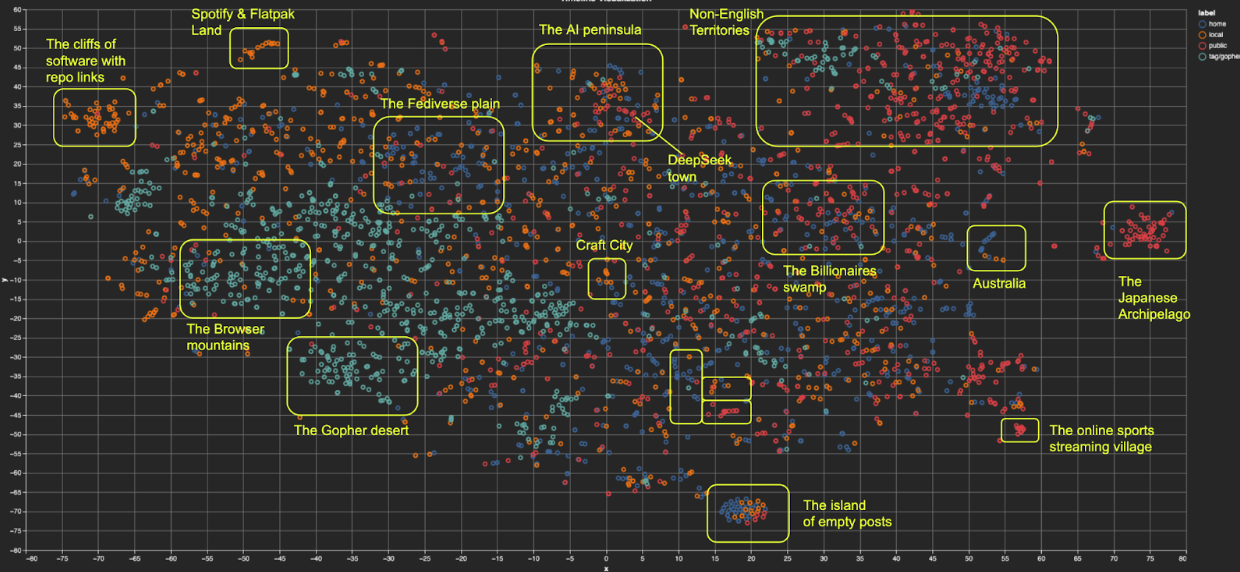
Embeddings Visualization. In this section, you can see posts from different timelines represented as points on a plane: You can click on a timeline label on the top right to highlight only posts from that timeline. If you select one or more points, you will see them in the table below the plot. By clicking on the column names (e.g. label, text) you can sort them, wrap text (to see full post contents), or search their content.
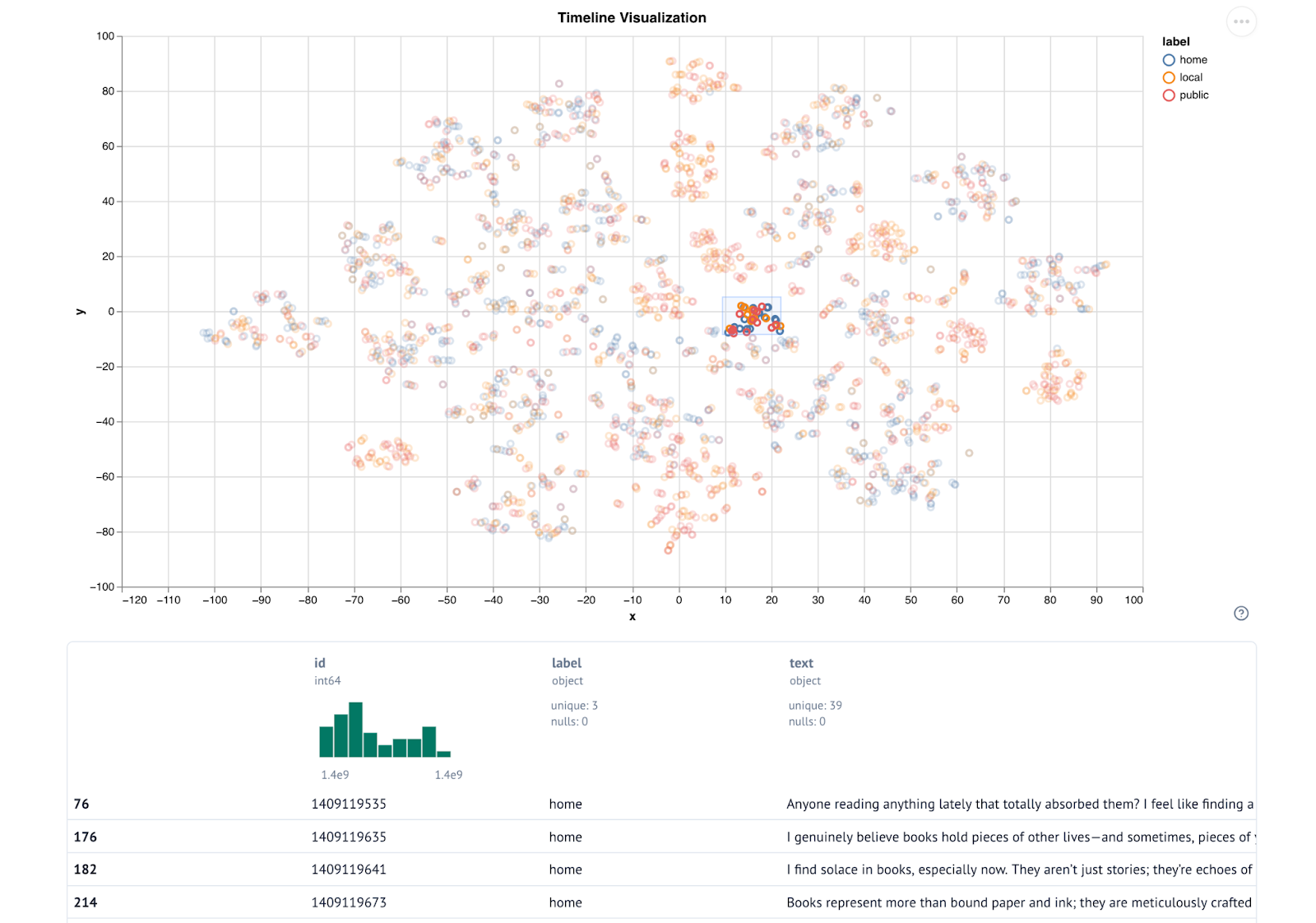
Timeline search. Here you can search for the most similar posts to a given one. You can either provide a row id (the leftmost column in the previous table) to refer to an existing post, or freeform text to look for posts which are similar in content to what you wrote.
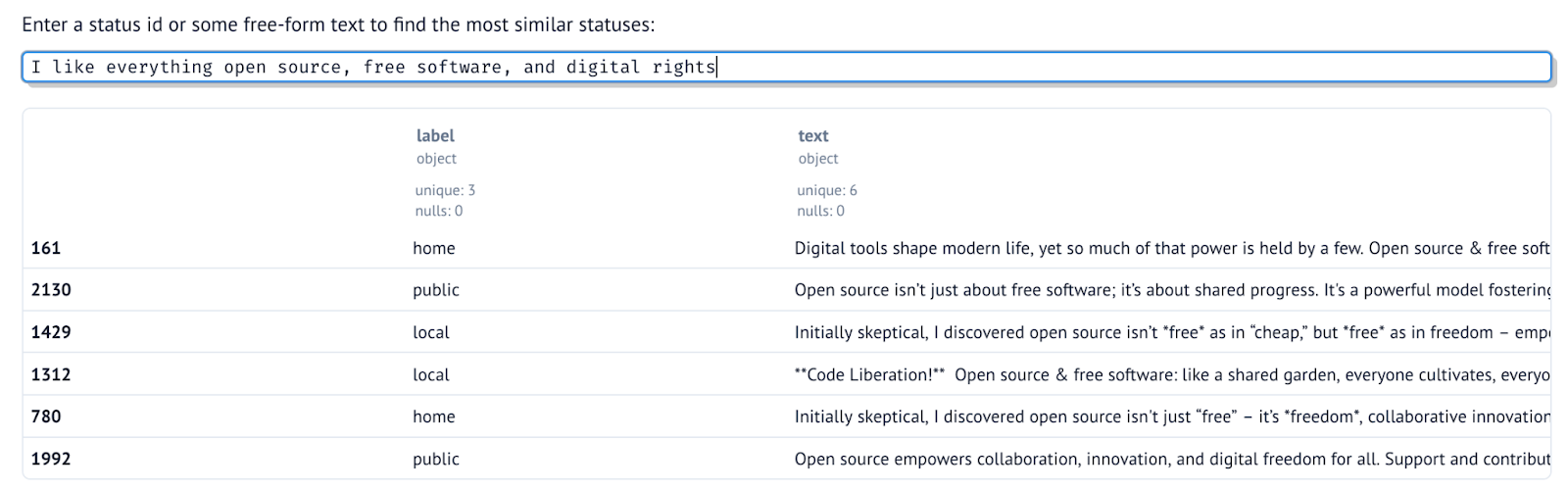
Timeline re-ranking. A score is assigned to each post in the timeline, with higher scores given to posts that are more similar to a set of other posts (in the specific case of the demo, statuses I shared from my personal Mastodon account). This score is then used to re-rank a timeline of your choice to prioritize those topics which are more present in the reference set.
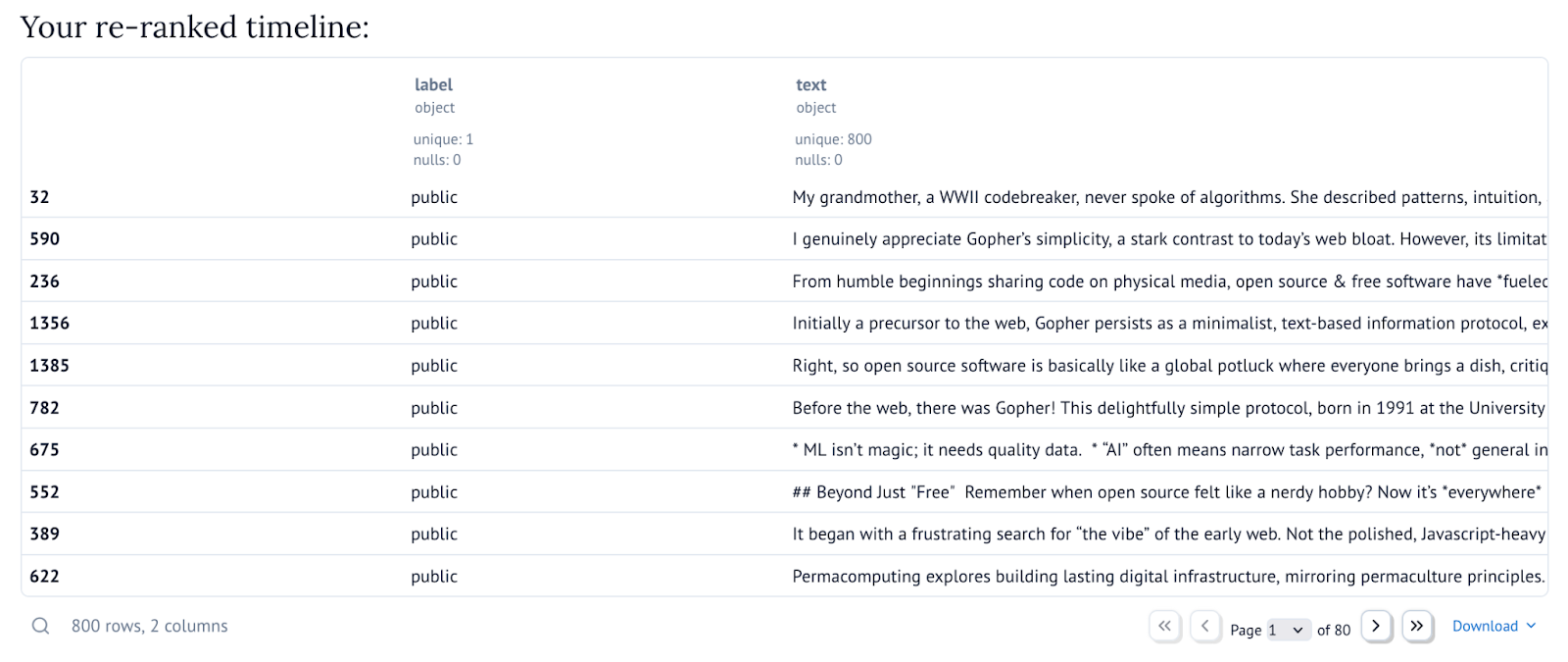
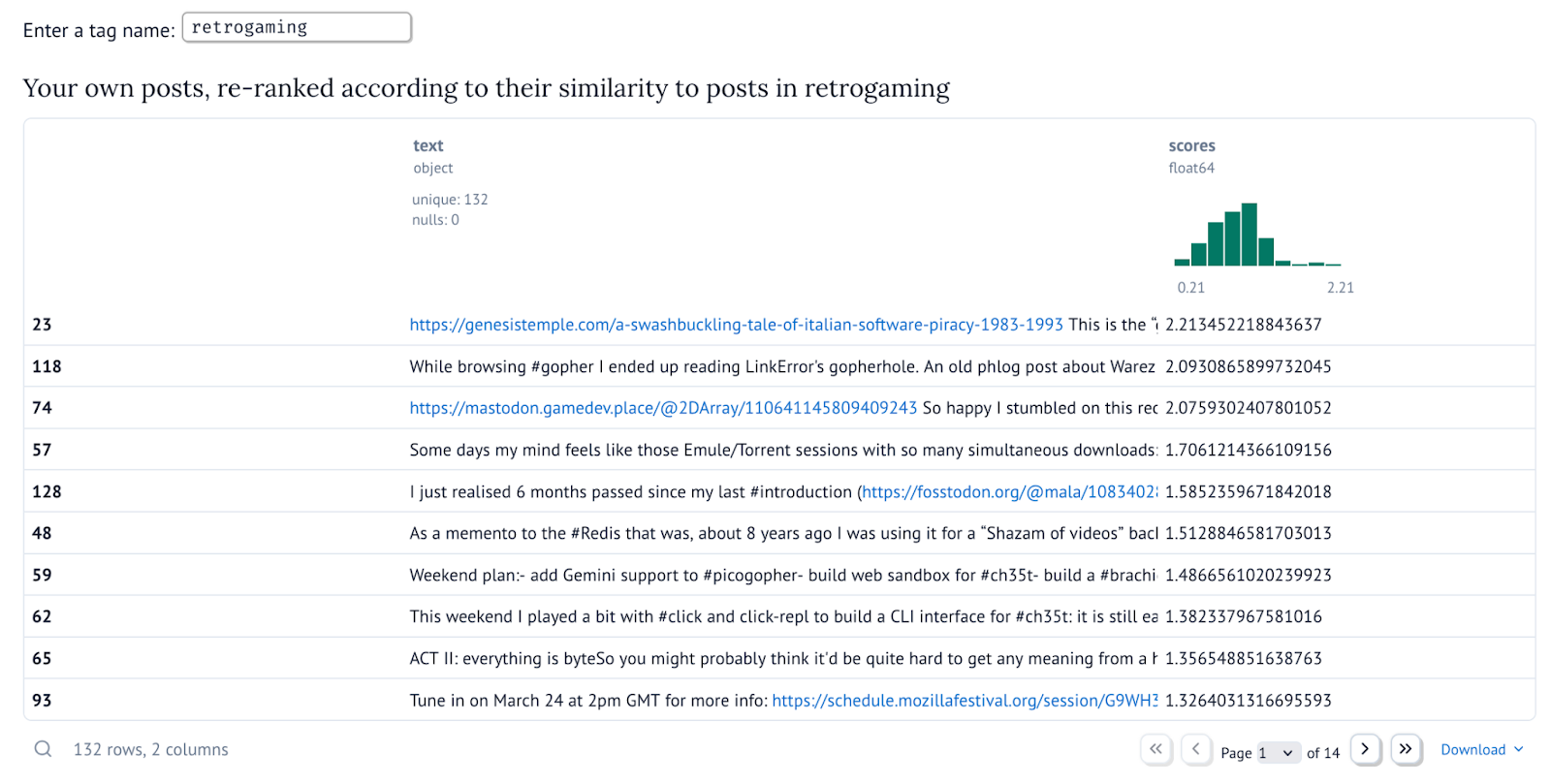
Re-ranking your own posts. Depending on the timeline you are considering, it might be more or less hard to understand how well the re-ranking worked. To give you a better sense of the effect of re-ranking, this section re-ranks an individual’s set of posts according to a topic identified by some well-known tag.
Customize it
Basically any component in BYOTA can be swapped with another one:
- Want to use another embedding model? The llamafile embedding server accepts model files as input parameters, so you can try your own.
- Do you prefer a different embedding server? The code already supports ollama and, more generally, other tools compatible with OpenAI’s API.
- Do you want to run the tool on another social media platform? Except for the code that downloads posts, BYOTA is platform-agnostic so you can just plug in a different client and get recommendations for your own favorite platform.
- Do you want to run different algorithms? We like your enthusiasm 😃 You can clone the repo and start editing python code with a simple
marimo edit notebook.py(check our customization guide). Anything, from alternatives to the simple dot-product re-ranker we have implemented, up to simple classifiers to be trained on top of the embeddings, sounds like an interesting idea, especially if it can run locally in a browser with WASM.
Conclusions
BYOTA started as a passion project, aimed at finding a more user-centric version of timeline algorithms. What really made it possible is the emergence of both tools that run powerful models even on commodity hardware, and applications that allow developers to easily share their code so it runs locally, directly in people’s browsers. Now that the technologies are available, we believe it’s a great moment to start building something together (we already said this was a call for action…).
If you are interested in BYOTA any contribution is welcome, not just technical ones:
- Try the demo and let us know what you think about it on the Blueprints Discord channel.
- Check out the project’s issues page on GitHub and comment on existing ideas or suggest new ones.
- Pick up some “Help Wanted” or “Good first issue” tasks if you want to get your hands dirty!
Discover this and other Blueprints we’ve released on our Blueprints Hub.



