
Evaluating DeepSeek V3 with Lumigator
A typical user may be building a summarization application for their domain and wondering: “Do I need to go for a model as big as DeepSeek, or can I get away with a smaller model?”. This takes us to the key elements: Metrics, Models, and Datasets.




We previously saw how to deploy DeepSeek V3 on a Kubernetes cluster using Ray and vLLM. The outcome of this step is a scalable API that one can leverage to evaluate a model with Lumigator.
A typical user may be building a summarization application for their domain and wondering: “Do I need to go for a model as big as DeepSeek, or can I get away with a smaller model?”. This takes us to the key elements:
- Metrics: Hard, cold scores that tell you how well a model performs for a specific dataset—often in comparison to some ideal ground truth.
- Models: Baselines to compare your candidates against.
- Datasets: One or more datasets drawn from the domain you care about that represent your use case.
Lumigator takes care of the first two and can show you how to prepare the third one. Let’s talk about the metrics first.
We evaluated DeepSeek V3 with three metrics: ROUGE (Recall-Oriented Understudy for Gisting Evaluation), METEOR (Metric for Evaluation of Translation with Explicit Ordering), and BERTScore. You can find out more information on why we chose these metrics in our previous blog post, On model selection for text summarization.
What do you need to remember from these metrics? Their limitations:
- ROUGE mainly counts word overlap between an ideal reference and what your candidate model produces, so it might miss summaries that use different words but convey the same meaning.
- METEOR can account for features that are not found in ROUGE, such as stemming and synonymy matching, along with standard exact word matching. Although more flexible, it can still struggle with very different phrasings.
- Finally, BERTScore generates embeddings of ground truth input and model output tokens and computes a similarity score between them. This makes it the most resilient to different phrasings from this list. However, it would still tend to be forgiving of summaries that are wrong but have a large lexical overlap.
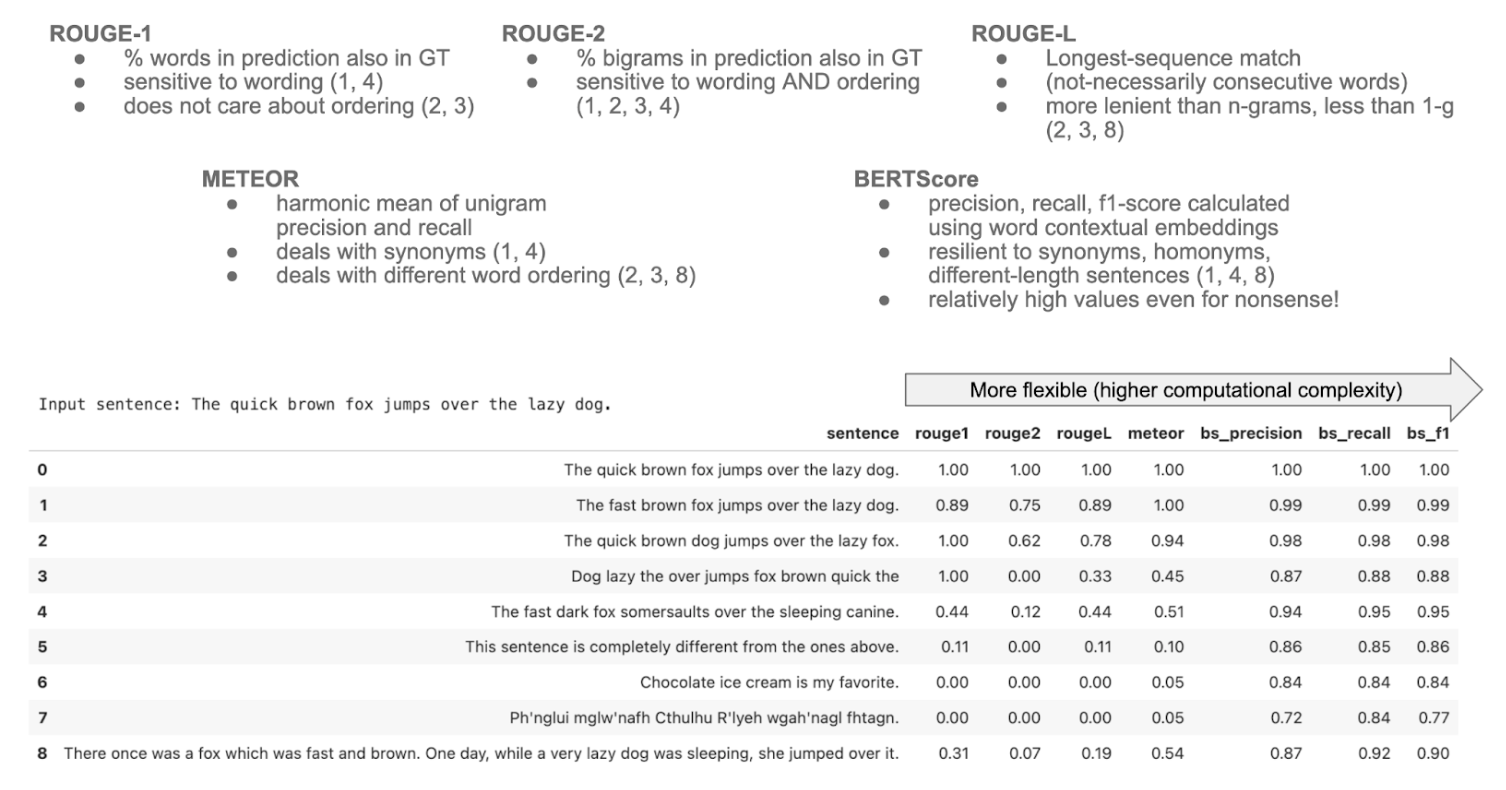
More visually, see how these metrics behave on some examples in this image taken from this Lumigator introductory notebook.
Now, let’s move on to the data and baseline model. We want to evaluate DeepSeek V3, offline, on 500 samples of DialogSum, and compare it to a small (1.6GB) baseline model, such as BART. You can read about choosing BART in this other post.
DialogSum is a large-scale dialogue summarization dataset consisting of 13,460 dialogues with corresponding manually labeled summaries and topics. The dialogues in the DialogSum dataset have three characteristics:
- Include more diverse topics.
- Have clear communication patterns and intents.
- Have a longer length compared with previous datasets. For example, the average length of dialogues in DialogSum is 39.8% longer than in SAMSum.
First, we evaluated DeepSeek V3 (BF16 variant) with the system prompt “You are a helpful assistant, expert in text summarization. For every prompt you receive, provide a summary of its contents in at most two sentences.” The results are as follows:
In comparison, adding BART to this table enables a head-to-head comparison of the two models, offering direct insight into their relative performance.
As you can see, in the case of BERTScore —the most capable metric amongst the ones we described— there isn’t much difference to justify the resources needed to run DeepSeek V3 locally. On the other hand, the differences in METEOR and ROUGE are not easily interpretable.
To better understand the limitations of each metric, let's examine the BERTScore result for a specific example. We have the following dialogue:
#Person1#: Hey Jimmy. Let's go workout later today.
#Person2#: Sure. What time do you want to go?
#Person1#: How about at 3:30?
#Person2#: That sounds good. Today we work on legs and forearm.
#Person1#: Hey. I just played basketball earlier, so my legs are a little sore. Let's work out on arms and stomach today.
#Person2#: I'm on a weekly schedule. You're messing everything up.
#Person1#: C'mon. We're only switching two days. You can do legs on Friday.
#Person2#: Aright. I'll meet you at the gym at 3:30 then.The summary provided by BART is as follows:
#Person1#: Hey. I just played basketball earlier, so my legs are a little sore. Let's work out on arms and stomach today. #Person2#: I'm on a weekly schedule. You're messing everything up. We're only switching two days. You can do legs on Friday.This is almost like doing extractive summarization. In this case, BERTScore F1 is 0.878, but even though the summary captures parts of the conversation about switching workout plans, it omits the initial workout invitation and does not include Person2’s final agreement to the new plan.
On the other hand, DeepSeek V3 appears to provide a more accurate summary, yet the difference in BERTScore F1 is minimal (0.888). For reference, here is the summary produced by DeepSeek V3:
#Person1# suggests working out at 3:30 but asks to switch the focus to arms and stomach instead of legs due to soreness from basketball; #Person2# reluctantly agrees to adjust the schedule and confirms the gym meeting time.Although BERTScore is our most versatile metric so far, it often assigns high similarity scores despite missing key contextual details.
Iterating and adding LLM-as-a-judge
Looking at these metrics, second decimal place differences between scores comparing a 1.5GB model against what ended up being a 1.3 TB model (1000 times bigger) doesn't bode well for the heavier model. But can we act on just those numbers?
Combine the vibe checks shown above with some common sense, and it pays to review the key factors:
- Is my dataset representative enough?
- Are my metrics good enough?
The definition of a good dataset highly depends on the use case and domain–and we'll see more in an upcoming post on selecting the right model for your precise job.
Regarding metrics, we felt Lumigator could do better, that is, closer to what humans tend to consider a "good" summary and more robust and flexible against paraphrasing. This prompted us to integrate the G-Eval metric. Namely, a particular implementation of the LLM-as-a-judge approach covering coherence, consistency, fluency, and relevance. These are shown to better align with human judgment than similarity-based metrics such as ROUGE and BERTScore. Each metric comes with a specific prompt that describes the respective evaluation criteria and steps (see the ones we used here). Let’s take another look now:
The new metrics seem to better capture the difference in quality between DeepSeek V3 and the smaller model, highlighting both the strengths and the weaknesses of both. For instance, DeepSeek was scored high for Fluency (as it better paraphrased summaries rather than simply extracting sentences) but was also penalized for Relevance (because its summaries contained more details than those provided in the ground truth). BART, instead, is heavily penalized on Fluency and Coherence, mostly due to issues in sentence composition and misrepresentation.
Conclusion
Foremost, all metrics have limitations. Much like sensors, they will only give you a partial view of what you are observing, not necessarily the full picture. This prompts us to keep extending Lumigator to include more expressive ones, such as LLM-as-a-judge metrics, and provide a more user-friendly result, providing a human-readable answer to the question “Which model is better for my use case?”
In an upcoming post, we will see how to use your own data to select the smallest model for a job.
What about your use cases? Have you run comparisons of multiple models with Lumigator? We’d be happy to hear how it goes and what other metrics would help you!



