
LLM evaluation at scale with the NeurIPS Large Language Model Efficiency Challenge
After a year of breakneck innovation and hype in the AI space, we have now moved sufficiently beyond the peak of the hype cycle to start asking a critical question: are LLMs good enough yet to solve all of the business and societal challenges we are setting them up for?

After a year of breakneck innovation and hype in the AI space, we have now moved sufficiently beyond the peak of the hype cycle to start asking a critical question: are LLMs good enough yet to solve all of the business and societal challenges we are setting them up for?
Given how complex the architectures of these models are, their variety, the rapidly-growing ecosystem around them, as well as their swift integration into a variety of products and services, it is crucial that the community starts seriously addressing the LLM evaluation minefield.
That is, how do we know if a model is any “good”?
In November 2023, our team at Mozilla.ai took part in one of the community efforts to focus on the evaluation of large language models fine-tuned on specialized data. The "NeurIPS Large Language Model Efficiency Challenge: 1 LLM + 1 GPU + 1 Day", led by PyTorch and Microsoft Research. We co-sponsored the challenge with AWS, Lambda Labs, and Microsoft. It brought together a number of teams competing in the craft of fine-tuning models. All the winners and results are here and the associated GitHub repositories are here.
This post shares our technical learnings from this competition, focusing on our finetuning and evaluation of the entries.
Competition Background
The idea for the competition started from the premise that current offline evaluation of large language models is an extremely complex and nuanced task, compounded by the speed of model development, continuously increasing options for evaluation metrics and their implementation, as well as lack of community consensus around metrics and pipelines. As an example, a recent survey paper on evaluation strategies included this chart of possible evaluation tasks and features:

In this light, one of the primary goals of the competition was to shed light on how people perform this kind of evaluation in practice, and to have the workflow out in the open, including a community component in a Discord server where entrants and evaluators could come together to discuss challenges and questions around the competition. The secondary goal was to release all of the artifacts of the competition as open source.
The primary machine learning objective was to be able to fine-tune LLMs in a 24-hour period on a single GPU. Fine-tuning is the process of taking a base model that’s already been pre-trained and updating all or a part of its parameters by continuing to train it on a curated dataset most suitable for the task at hand. When we fine-tune, we change the “flavor” of the model, or the way it responds to questions or generates text to fit more specific use-cases. For example, we might fine-tune a generalist model with code samples to better enable code autocompletion, or we might include medical data specific to cardiology, or from texts from our group chat to make it sound more like our friends, or even with data from card text to help us play Magic the Gathering.

In the process of fine-tuning, we freeze most of the weights of the pre-trained model and update a subset of the model's parameters. Many experiments show that one can dramatically reduce the computational cost of retraining the model with a relatively small performance decrease by updating the last few layers, and that in some cases fine-tuning too many layers can be detrimental.
Although pre-training is often the most compute-intensive task, taking over a month in some cases, fine-tuning can also be complex depending on the model architecture. The goal of the challenge is to be able to perform fine-tuning in the course of 24 hours on a single GPU, in stark contrast to the scope of most pre-training and fine tuning jobs, and democratize the use of open-source LLMs and open-source datasets beyond the few teams that have access to state of the art hardware.
Competition Hardware
The two proposed hardware tracks were on Nvidia RTX 4090 or A100 GPUs. The key difference between 4090s and A100s is their RAM capacity: 4090s are aimed primarily at gamers and A100s are designed for HPC tasks. 4090s have less RAM and are significantly less expensive.

Once the challenge team had created a list of the final contestants and their final code repositories, Mozilla.ai’s task was to:
- Replicate fine-tuning on a subset of the submitted models, (for both the 4090 track and the A100 track)
- Store the resulting artifacts in public-facing HuggingFace repos, and
- Test HELM offline evaluation on the generated model artifacts. We also later performed evaluation of these models internally.
.png)
Using HELM and Offline Evaluation
The evaluation itself was carried out by running a subset of HELM tasks. HELM is a framework developed by Stanford University for the public evaluation of large language models. It includes the ability to run evaluation tasks on over 30 LLMs and 10 scenarios, including popular offline evaluation scenarios such as MMLU and GSM8K.
When we perform evaluation for machine learning models, there are two modes, each of which seek to answer the question: “is the model we trained good enough to generalize beyond its training data for the machine learning task we want it to perform?”
- Offline evaluation: We train a model and, using a holdout test set from our training data, we evaluate on metrics like precision, accuracy, recall, NCDG, RMSE from “classical” machine learning and BLEU and ROUGE for large language models, as relevant for our machine learning domain. The essential question we are trying to answer is, “Given the ground truth in your test data, how well does the trained model make predictions?” The closer the match, the better it is.
- Online evaluation: We ship the model to production as a customer-facing application or feature, (i.e. ChatGPT or Bard) and have people use it and give implicit or explicit feedback on whether the results were good. This could involve looking at user activity or text input/output in the application where we deploy our model. The essential question we are trying to answer is: “Given the live model, how good do people think it is?” The more people use it or the more relevant the results, the better the model actually is. Because offline and online scores don’t always match, it’s important to assess whether offline metrics are good proxies for online performance.
In “traditional” machine learning, particularly in class-based supervised learning tasks, evaluation is quite straightforward: if we have a model that predicts, based on someone’s X-rays, whether they have lung cancer, we can collect x-rays that have already been classified by doctors and see if the model we learned predicts the same class (YES/NO) for those samples.
In problems like recommendations and information retrieval ranking, which gets closer to the domain of LLMs, this gets harder. How do we know a “relevant” result was returned? Usually online ranking is the best fit here, but offline metrics like NDCG are considered good offline proxy metrics. They offer the ability to compare a returned recommendation/search prediction to a relevance judgment list and calculate the difference both in elements served and position of those elements, given the narrow confines of a specific task.
Taking this to the next level, what if we have a model that completes an endless number of different machine learning tasks: summarization, autocompletion, reasoning, generating recommendations for movies and recipes, writing essays, telling stories, translating documents, generating good code, and on and on? Evaluation becomes much harder, almost as hard as deciding if a real person will consistently give you trustworthy information.
Combine this problem with the idea that:
- model results are non-deterministic (aka any given question could generate different responses at different times),
- there is a growing number of open-source and proprietary models, all with varying details about their training data and architectures, and
- a number of different frameworks for thinking about evaluation
- we have leakage of test data into the training set, leading to a higher benchmark result.
And we now have a recipe for a very complicated problem.
What is an evaluation framework?
There is a distinction that should be drawn between evaluation benchmarks and frameworks. Benchmarks refer to the combination of the dataset and the task presented to the model using that dataset. For instance, the popular MMLU benchmark contains a dataset and is most commonly presented to the model as a multiple-choice question-answering task. The benchmark covers 57 tasks including elementary mathematics, United States history, computer science, and law.
An evaluation framework manages chaining together all of the pieces of running a benchmark (or collection thereof) against a model. This includes:
- Loading the model (which might be in-process, or just bindings to a remote inference server)
- Keeping track of multiple benchmarks
- Downloading and preprocessing the benchmark datasets so that their format is compatible with model evaluation as carried out by the framework
- Querying the model with elements of the benchmark
- Aggregating results and reporting metrics on the model outputs
HELM is one of the most frequently-used evaluation frameworks that includes multiple tasks across multiple views. It is a holistic benchmark meant to cover a broad range of scenarios for machine learning tasks performed by LLMs. This includes:
- MMLU (Massive Multitask Language Understanding) - Question Answering which includes questions across a number of different topics
- Narrative QA - A common strategy for assessing the language understanding of models, i.e. their ability to comprehend text, is to demonstrate that they can answer questions about documents they are given, akin to how reading comprehension is tested in children when they are learning to read.
- And many others that fall into the top categories of the HELM paper. Its output looks like this:

Challenges with Interpreting LLM Evaluation Outputs
For any given task, the evaluation works like this at a high-level: the model generates an answer as text, and that text is checked, in some way, against the text of the evaluation dataset. The calculation of the metric is how different the generated text is from the expected output.
As a concrete example, let’s take MMLU, one of the most commonly mentioned and used benchmarks. To attain high accuracy on this test, models must possess extensive world knowledge and problem-solving ability.
Here’s an example of an MMLU question:

That example, along with a sample answer, is tokenized and sent to the large language model, which returns either single tokens with probabilities, or a single text completion. In the case of the specific HELM implementation of MMLU, the original model outputs text probabilities, which we then use to generate a complete text. That text, the answer, is then compared to the original text and answer. Since the model is based on probabilistic behaviors, it’s given 5 chances in a few-shot setting to correctly generate the correct answer. The model gets one point for each answer it gets right, and it gets a score as a percentage of right/total questions per category (i.e. humanities, science, etc.), and then those answers are averaged across the four possible categories MMLU covers for a final percentage.
An important note covered in the HuggingFace post is that there can be multiple implementations of the same metric spread across different libraries, and even, sometimes, in the same library, so we start to see why evaluation is so hard.
Each benchmark, such as MMLU, BBQ, and GSM8K, performs similar work and generates a percentage that can usually be interpreted as the number of answers the model got right in a few-shot setting. The following image provides a summary of the different evaluations that were run automatically by the NeurIPS Discord bot on every submitted model:

This was the initial set of tasks, along with a set of hidden tasks, including sam_sum and corr2cause, run for the final evaluation. The final aggregate evaluation score for each entry was calculated by the geometric mean across all evaluation tasks as follows:
score=π(mean-win-rate(task))Our Role in NeurIPS Evaluation
Our role was to act as an evaluator and manually inspect the entries to make sure they fulfilled the model criteria and rules of the competition. Given a submission, our first task was to gather answers for a set of questions which included:
- Did entrants use an approved base model (open base model without instruction-tuning)?
- Did all the model infrastructure (i.e.
Dockerfiles) work? - Did the contestants use a fine-tuning dataset that was open-source and did not include any data generated with large language models?
- Did the contestants train on the test set?
The following task was to replicate fine-tuning runs of the artifacts and make sure that we got valid checkpoint weights to pass into evaluation. Evaluation was carried out in two stages:
- the first was performed automatically by a Discord bot which accepted at most 3 submissions per day,
- the second was done by the organizing PyTorch and MSR team.
The first stage used a subset of HELM tasks and training on HELM data was considered still acceptable as the second stage used a new, held-out dataset which had never been made publicly available before.
HELM is a library that runs Python process that has a number of tests that are run according to a spec file. It is modular and extendable, offering the possibility to connect to a plethora of different models either stored locally, made available on hubs such as HuggingFace, or accessible via APIs such as OpenAI’s.
Each model is defined in a YAML file together with the client class used to access it. For the NeurIPS challenge, a special NeurIPS/local profile has been created which uses the HTTPModelClient to send requests to the model via HTTP POST requests.
The challenge organizers provided example Dockerfiles with a FastAPI-based HTTP wrapper around the fine-tuned models (see e.g. the lit-gpt-based submission here) that implements the server-side part of the HTTPModelClient interface.
Internally, HELM evaluation was performed following documentation here. The steps involved included:
- installing HELM as a Python
pipexecutable - creating a
run_specs.conffile holding a list of the experiments we want to perform - running helm:
helm-run --conf-paths run_specs.conf --suite v1 --max-eval-instances 10 - summarizing the results:
helm-summarize --suite v1 - serving the results via an HTTP server:
helm-server
Mozilla.ai’s Evaluation Infrastructure
Mozilla.ai is using Coreweave as our GPU provider. We run our GPU-based inference and evaluation on Kubernetes. In order to operationalize and make the evaluation process standard,
We created a Kubernetes Helm chart (not to be confused with HELM) that launched two pods:
- a
modelServerpod with GPUs and the model served via FastAPI and - a
helmServerpod from the NeurIPS repo that’s CPU-only. It executes the actual HELM evaluation by running HTTP inference requests against the modelServer:
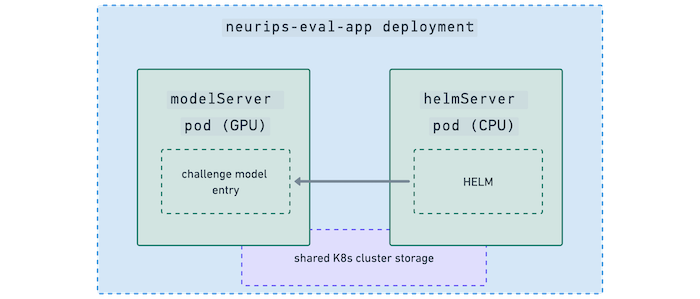
You can see the sample infra templates we used here in our repo. The organizers made a sample submission pipeline available here, and we used this as our baseline.
We also included external storage in the form of Ceph-backed PVCs and ended up having to increase storage on the fly to accommodate the growing model and artifact sizes. Storage is a key aspect of machine learning workflows with large artifacts, in K8s since pods can be reallocated, we need to attach NAS (network-attached storage), which are typically block storage. For ML specifically, we need fast sequential reads for large model objects that we can stream into K8s pods. Since K8s is developed at the deployment/application level, storage is provisioned as part of a K8s pod that is available to all containers in a pod. Containers are immutable, and so for stateful applications we need a way to store data outside the container, within a pod, and across pods as a shared state. We do this using a PVC, which is dynamically-provisioned storage to allow a pod to use shared cluster storage.
We ran fine-tuning for our entries using a variation of this setup on Coreweave and were able to run parallel fine-tuning jobs over the course of a week to provide a fast turnaround to competition entrants and to move entries into the hold-out evaluation phase. Finally, the evaluated model artifacts were passed to the workshop organizers’ team for review.
Our Technical Learnings
The challenge was a fantastic place to learn more about what the industry was thinking about and working on with respect to LLM compression, as well as stress-test our own infrastructure. At a high level, our key takeaways from the competition were on the model side and the infra side. Here are a few of our notes:
Models
- Many of the entrants used LLaMA-2 as the base-model. Many were based on llama-recipes, a repo hosted by the Meta team.
- Mistral, a late entrant, was also frequently used as a baseline.
- A few of the entries used Qwen, a lesser-known Chinese model developed at Alibaba cloud that has a restrictive license for commercial use. Reviews of the model itself as a base model are fairly mixed. And there are some interesting experiments with its alignment here (Qwen/Qwen-14B).
- Most of the models were from the HuggingFace ecosystem and the artifacts and adapters were then loaded back to HuggingFace Hub.
- Data curation, and more specifically, manual data curation proved to be extremely important. Open-source data was used and many competitors chose not to create their own datasets, filtering out LLM-generated responses where they were able.
- All teams took a strategy of preparing a model that would be able to generalize to unseen tasks given the unknown nature of the holdout dataset.
- Qwen proved to be an extremely resilient model, and Mistral 7B also had fairly good, general performance.
- Many of the models used PEFT - parameter-efficient fine-tuning, an umbrella term for a variety of techniques used to reduce the number of parameters that need to be updated during fine-tuning. One of these approaches is LoRA, Low-Rank Adaptation of Large Models that works by inserting a smaller number of new weights into the models, training only on these, which learn the low-rank approximation of the original parameters. Generally LoRa uses 16 bit, but can be compressed down to 8 and even 4-bit representations. Here are some examples of different result representations using the various compression methods. Note that quantization might impact different models in a different way, and using e.g. available benchmarks as a reference to predict their behavior might be useful (for instance, one can look at the performance of a given model on the Open LLM Leaderboard for different precision values).
- MMLU was a key evaluation task, and top datasets included open platypus and LIMA.
Infrastructure:
- From the perspective of producing machine learning artifacts, the biggest learning was that reproducing ML artifacts is still extremely challenging, even with frozen Docker images. There is a wide range of experience with Docker across the machine learning community ranging from engineers who work with production every day to students working with the technology for the first time. In addition, Docker has a wide range of best practices, commands, and entry points, leading to a wide variety of image types. Each entry had its own Docker complications, for example one of them included the HELM server as part of the model server versus as a standalone which involved some separation work, and one of them generated a Docker artifact that was 100GB because multiple versions of the training data were baked into the image.
- Kubernetes is by its nature well-suited to running web apps and processes and not keeping state by default (i.e. all pods are resilient to failure and ephemeral) that’s required in intensive machine learning applications which makes persistent storage critical. We initially did not include a PVC/PV as part of the deployment which meant that all checkpoints were saved on the pod and not resilient to pod failures and restarts.
This can be very hard when you’re running 15+ hour training jobs. As a result, a critical aspect of this is both shared storage and model checkpointing into shared storage. We didn’t use the Ray framework for this but it will be interesting to see how Ray handles all of this internally. - Working with HELM can be challenging in the context of the competition since it’s not designed to function as a stand-alone web server that has exception handling needed for multiple runs. The model server should, in theory, work out-of-the box by running helm-server. But, the model evaluation itself was extremely hard to reproduce due to the brittle nature of HELM; i.e. they have pip releases and also releases to main, and the two don't coincide. In one case, an evaluation stopped running halfway through with the following error:
helm.benchmark.runner.RunnerError:
Failed runs: ["summarization_cnndm:temperature=0.3,
device=cpu,model=neurips_local,max_eval_instances=9"]Looking into this, it appears the reason was that HELM used to pull data for a summarization task from a server that was down at the time. The problem was promptly fixed but that meant one had to download a new version of HELM. This required us to change the pinned requirements and rebuild the Docker image. We tried ways to work around this, including rewriting code to implement HELM as a web server. Eventually we built a Docker container with the HELM evaluation framework, added it to our Coreweave Container Registry and created it as part of our training deployment, with evaluation checkpointing into shared storage so that intermediate results didn’t get lost.
Conclusion
The competition was a fantastic way to gain insights into the living, breathing space of large language model work and all the challenges associated with it. It’s become clear that there are many challenges to working with and evaluating open-source large language models in an efficient and practical way, both the modeling perspective and from the infrastructure perspectives, and framework needed to run large-scale open evaluations.
On the modeling side, there is a steady stream of new models. For example, Qwen just came out as the NeurIPS competition was starting and Mixtral, the mixture of experts model that has quickly become a staple of the top of the leaderboards, was weeks away from being released. These constant new releases lead to a critical need to evaluate and compare artifacts as they come online. Additionally, the need to be able to evaluate models from a variety of sources (locally fine-tuned, available as APIs, and shared via hubs like HuggingFace) means the need for tooling and workflows to be able to consolidate them.
On the evaluation side, there are still a plethora of evaluation tasks and frameworks to choose from, each of which have their own implementations, focuses, and software architectures. Internally, we’ve standardized on (and contributed to) lm-evaluation-harness for offline model evaluation, but it’s still important to keep an eye out for new metrics and papers and adapt.
On the infrastructure side, although Docker images are a standard for industry, the velocity of moving requirements in growing machine learning libraries, as well as the difficulty of reproducibility, even with specifications, mean the need for clear, reproducible infrastructure and methodologies for running evaluation.
At Mozilla.ai we believe in the importance of establishing robust and transparent foundations for the evaluation field as a way of working toward a trustworthy AI stack. This is why we're working on a number of tracks of work to support this. On the experimentation side, we are focused on research approaches that allow for a clear definition of metrics and transparency and run repeatable evaluations. On the infrastructure side, we’re developing reliable and replicable infrastructure to evaluate models and store and introspect model results. We’re excited to continue developing these internally at Mozilla.ai and sharing more of our work publicly this year.
Bibliography
- Castells, P., & Jannach, D. (2023). Recommender Systems: A Primer (arXiv:2302.02579). arXiv. http://arxiv.org/abs/2302.02579.
- Chang, Y., Wang, X., Wang, J., Wu, Y., Yang, L., Zhu, K., Chen, H., Yi, X., Wang, C., Wang, Y., Ye, W., Zhang, Y., Chang, Y., Yu, P. S., Yang, Q., & Xie, X. (2023). A Survey on Evaluation of Large Language Models (arXiv:2307.03109). arXiv. http://arxiv.org/abs/2307.03109.
- Gliwa, Bogdan, et al. “SAMSum Corpus: A Human-Annotated Dialogue Dataset for Abstractive Summarization.” Proceedings of the 2nd Workshop on New Frontiers in Summarization, 2019, pp. 70–79, https://doi.org/10.18653/v1/D19-5409.
- Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., & Steinhardt, J. (2021). Measuring Massive Multitask Language Understanding (arXiv:2009.03300). arXiv. http://arxiv.org/abs/2009.03300.
- Jiang, A. Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D. S., Casas, D. de las, Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L. R., Lachaux, M.-A., Stock, P., Scao, T. L., Lavril, T., Wang, T., Lacroix, T., & Sayed, W. E. (2023). Mistral 7B (arXiv:2310.06825). arXiv. http://arxiv.org/abs/2310.06825.
- Jin, Zhijing, et al. Can Large Language Models Infer Causation from Correlation? arXiv:2306.05836, arXiv, 31 Dec. 2023, http://arxiv.org/abs/2306.05836.
- Kaddour, Jean, et al. Challenges and Applications of Large Language Models. arXiv:2307.10169, arXiv, 19 July 2023, http://arxiv.org/abs/2307.10169.
- Lee, Jaejun, et al. What Would Elsa Do? Freezing Layers During Transformer Fine-Tuning. arXiv:1911.03090, arXiv, 8 Nov. 2019, http://arxiv.org/abs/1911.03090.
- Liang, P., Bommasani, R., Lee, T., Tsipras, D., Soylu, D., Yasunaga, M., Zhang, Y., Narayanan, D., Wu, Y., Kumar, A., Newman, B., Yuan, B., Yan, B., Zhang, C., Cosgrove, C., Manning, C. D., Ré, C., Acosta-Navas, D., Hudson, D. A., … Koreeda, Y. (2023). Holistic Evaluation of Language Models (arXiv:2211.09110). arXiv. http://arxiv.org/abs/2211.09110.
- Narayanan, D., Shoeybi, M., Casper, J., LeGresley, P., Patwary, M., Korthikanti, V. A., Vainbrand, D., Kashinkunti, P., Bernauer, J., Catanzaro, B., Phanishayee, A., & Zaharia, M. (2021). Efficient Large-Scale Language Model Training on GPU Clusters Using Megatron-LM (arXiv:2104.04473). arXiv. http://arxiv.org/abs/2104.04473.
- Tikhonov, A., & Yamshchikov, I. P. (2023). Post Turing: Mapping the landscape of LLM Evaluation (arXiv:2311.02049). arXiv. http://arxiv.org/abs/2311.02049.
- Zhou, Kun, et al. Don’t Make Your LLM an Evaluation Benchmark Cheater. arXiv:2311.01964, arXiv, 3 Nov. 2023, http://arxiv.org/abs/2311.01964.



