
Smarter Prompts for Better Responses: Exploring Prompt Optimization and Interpretability for LLMs
Generative AI models are highly sensitive to input phrasing. Even small changes to a prompt or switching between models can lead to different results. Adding to the complexity, LLMs often act as black-boxes, making it difficult to understand how specific prompts influence their behavior.




Generative AI has taken center stage in reshaping how we work and interact with technology. While the capabilities of Large Language Models (LLMs) have advanced rapidly, they remain highly sensitive to how we phrase our inputs. Even small changes to a prompt, switching between models, or using different versions of the same model can lead to different (and not always improved) results, often leaving users frustrated. Adding to the complexity, LLMs function largely as black-boxes, making it difficult to understand how specific prompts influence their behavior. Ineffective inputs can ultimately lead to real-world problems, such as unreliable or biased responses, which can undermine user confidence and limit the practical value of these models.
That’s where prompt engineering comes in. Crafting effective prompts is a critical step in aligning model behavior with user intent. However, manually optimizing prompts or interpreting model outputs is a trial-and-error process that is time-consuming and difficult to scale, especially as AI systems are deployed more widely across industries.
To address these challenges, the field is shifting towards more automated, interpretable, and scalable approaches to prompt engineering. And the market is taking note. This study shows that the global prompt engineering sector was estimated at $380 million in 2024, and is projected to surge to $6.5 billion by 2034, reflecting a compound annual growth rate of 32.9%. This growth is fueled not just by the rise of AI agents and task-specific models, but also by demand from sectors like healthcare, finance, insurance, legal, automotive, or logistics, where optimized and trustworthy AI outputs are mission-critical.
As tools evolve and regulation increases around AI transparency and safety, prompt engineering will play a central role in shaping responsible and effective AI systems. In this blog post, we will explore two areas that are gaining traction to empower developers and teams to get the most out of their AI systems.
- Prompt Optimization: Tools and frameworks that help users craft better-performing prompts with less trial and error.
- Prompt Interpretability: Methods that offer transparency into how prompts influence model outputs, helping users debug and refine their interactions more effectively.
Prompt Optimization
As previously mentioned, trying to engineer the best prompts through trial-and-error can be time-consuming. While "prompt templates" can work well in some situations, they often don't adapt easily to different inputs or when switching to another language model, which may lead to inconsistent results.
This is where automatic prompt optimization, with frameworks such as DSPy and TextGrad, could be useful. DSPy advocates for prompt programming, a structured and declarative approach rather than manual prompt engineering. A DSPy optimizer typically requires the following:
- A DSPy program (which consists of signatures and modules that specify your initial prompt outlining what you want the LLM to do, along with input and output definitions).
- A metric function that evaluates the quality of your program's output.
- A small set of training inputs, which can sometimes be as few as 5 or 10 demonstration examples of the task.
DSPy comes with several optimizers to choose from. We discuss two of the most popular ones:
- BootstrapFewShot: This optimizer works by using existing examples from the training dataset and/or generating a set of effective demonstrations (few-shot examples created with the help of the same LLM or an advanced "teacher" LLM). These demonstrations are then directly added to your original prompt. This is especially useful when you don't have a lot of labeled training data.
- MIPROv2: An approach that uses Bayesian optimization and is capable of simultaneously optimizing both the natural language prompt instructions as well as the few-shot examples. The steps taken by the optimizer are well described in the official documentation.
We experimented with DSPy on the task of summarization with the DialogSum dataset. A portion of the data (50 rows) was set aside for prompt optimization ("training"), and the rest was used for actual LLM evaluation to compare the performance with and without optimized prompts. The metric used in the optimization process was METEOR (a word-overlap-based metric for evaluating text generation quality that also incorporates synonymy and stemming), and the LLM evaluated was ministral-8b-latest. Going beyond the demo, one can swap out both the model and the metric with relevant alternatives of choice.
Using Gradio, we built a simple app to carry out the evaluation from a GUI: a) without prompt optimization, and b) with optimization using the two algorithms described above. The goal with the Gradio app was to abstract away all of the DSPy implementation details and make the optimization process more beginner-friendly. You can test out the app by following the instructions in this repo: https://github.com/mozilla-ai/visual-dspy
Looking at the evaluation results, we found that the biggest improvement came from including few-shot examples in the prompt. The MIPROv2-optimised prompt then provided an additional, albeit smaller boost to the METEOR score.
A significant advantage that DSPy offers is that when you modify your code, data, evaluation metrics, or even switch to a different language model, you can simply recompile your DSPy program, and the framework will automatically optimize the prompts to suit these new conditions. This eliminates the need for manual prompt rewriting and testing with every change.
Despite its capabilities, one main challenge with DSPy is that it has a steep learning curve. This can significantly slow down non-technical or non-ML users who just want effective prompts in their applications and shouldn't need to invest hours or days in mastering a framework. A key step forward would be to lower the barrier to entry with the help of user-friendly interfaces.
While automatic prompt optimization aims to generate effective prompts, understanding why certain prompts work better than others could be an important aspect in certain application areas, which is what we look at in the next section.
Prompt Interpretability
In Machine Learning, for an algorithm to be interpretable, it means being able to understand causal relationships between its inputs and its outputs. For language models in particular, one form of interpretability would be to be able to understand which parts of the prompt contribute to a given LM response or a part thereof.
Prompt interpretability approaches can vary across different dimensions:
- Scope: They can appear as relatively small, self-contained libraries or full-fledged frameworks where prompt interpretability is just one of the many features.
- Task: Depending on the LLM downstream task, they can be applied to e.g. classification, open text generation, etc.
- Granularity: They can deal with text at different levels of granularity, from tokens to words, sentences, and so on.
- White- vs black-box: Some approaches, for instance, those relying on gradient-based methods, require direct access to the model, while others are able to provide useful information just using the model as a black-box.
These dimensions are orthogonal, and some of the most popular interpretability tools show a few of them each. For instance, Google PAIR’s LIT (Learning Interpretability Tool) is a framework-agnostic, “visual, interactive ML model-understanding tool that supports text, image, and tabular data”. It has a Web UI that can be served standalone or inside a notebook environment. It implements token-based salience using both gradient-based approaches and LIME as a black-box one (however, this is specifically targeted at classification/regression tasks, rather than text generation), and sequence salience (tutorial, demo) with a granularity that ranges from individual tokens to words and whole sentences.
Meta’s Captum is a Python library for model interpretability and understanding in PyTorch. It implements a large variety of algorithms for attribution and interpretability on different data types, and while it looks more directed towards “developers who are looking to improve their models”, it presents a large tutorials section which can guide you through its features.
Putting ourselves in the shoes of a builder who wants to create a new AI-powered application using available open language models, we decided to experiment with developing a lightweight, self-contained CLI prompt interpretability tool which can work in a black-box fashion. Taking inspiration from PromptExp, we implemented a perturbation-based approach to measure the saliency of a text segment, one that relies on the semantic similarity of the perturbed prompt with respect to the original one. In practice:
- The original prompt is divided into segments (we chose to use words for our experiment, but they could be as small as tokens or as large as sentences, depending on the desired granularity).
- Each segment is systematically masked, generating as many perturbed versions of the prompt as there are segments. Each perturbed prompt is then sent to the model to be evaluated.
- Semantic similarity is calculated between the original response (i.e., the one for the unperturbed prompt) and all others. Segments that, when masked, cause larger deviations in the output are considered more salient or important to the final result.
Our prompt saliency tool allows for some customization with respect to the model to evaluate (all those supported by LiteLLM) and the one used for embeddings (all those supported by SentenceTransformers). Despite being so simple, we can already use it to better understand some peculiar model behaviors, for instance:
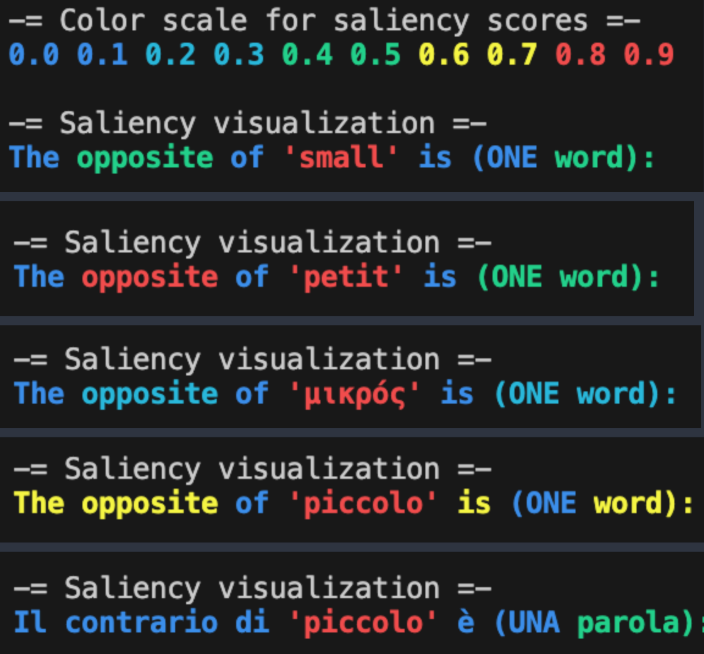
- Dependence on input language. We asked GPT-4o for the opposite of a word, requiring the answer to be one word too. As expected, in English, the most salient parts of the sentence are the word itself, the word “opposite”, and the request for a one-word output. If we use translations in different languages for the word “small”, these differences are quite consistent, except for Italian. Looking at model explanations, we found that this word in English has a different meaning (not just “small”, but also a musical instrument whose opposite is “contrabass”). If we ask the same question directly in Italian, the behavior is more similar to what we’d expect. Interestingly, less powerful models (e.g. a quantized version of Gemma-3:27b running locally) do not exhibit the same kind of behavior.
- Model biases. We asked GPT-4o to write the code for a function returning the factorial of an integer number. We were surprised to see that while “factorial” was definitely a salient term, the programming language we had specified (Python) was not. The reason was that, when the language was not specified, the model assumed Python by default. Changing to another programming language showed that other choices for the language were actually salient words in the prompt.

Conclusion
Prompt optimization and interpretability are essential for building AI systems that are not only effective but also explainable and reliable. Tools like DSPy offer a structured, automated approach to prompt optimization using few-shot examples and by re-writing the LLM instructions, which eventually could lead to improved task performance. On the prompt interpretability side, the prompt saliency tool helped uncover dependence on input language and hidden model biases.
Curious to dive deeper or test these approaches yourself? Explore our repos on GitHub for DSPy's prompt optimization and prompt saliency for interoperability, and let us know your results!



