
Structured Question Answering
When deciding on a new Blueprint, we focus on selecting an end application that is both practical and impactful, along with the best techniques to implement it. With endless possible applications of LMs today, selecting one that is actually useful can be challenging.


Why Question Answering?
As described in the blog post Introducing Blueprints, we want to help developers build AI applications using open-source tools and models. When deciding on a new Blueprint, we need to pick an end application to showcase and the techniques to implement it. The possible applications of LMs these days are endless, so it is hard to pick one that could be actually useful.
Fortunately, I frequently play board games where I spend countless hours poring over rule books, debating the finer points, and seeking answers to specific questions that arise during gameplay, as any avid board game enthusiast does. I thought using AI for answering questions about board games was something I, and probably every other board gamer out there, might find useful.
Why Structured Question Answering?
With that idea in mind, we looked for publicly available datasets that could help us, and found some that initially seemed relevant, such as BoardGameQA, Natural Questions, HotPotQA. However, these datasets were ultimately more geared towards academic research with questions that felt somehow artificial (designed to showcase a point rather than reflecting real world usage) and didn’t quite fit our intended purpose. Looking at how humans find answers in a board game rule book, we tend to follow a common pattern:
- Skim through the index and/or headings to find a relevant section.
- Navigate to the section to find the answer.
- Repeat the process if we don't find the answer in that section.
This actually applies not only to board game rule books but to many other types of structured documents like technical documentation, scientific reports, etc.
Before jumping into building a solution, we decided to build a small benchmark called Structured Question Answering, since we are focusing on documents that have been explicitly and intentionally structured into sections.
The Structured QA Benchmark
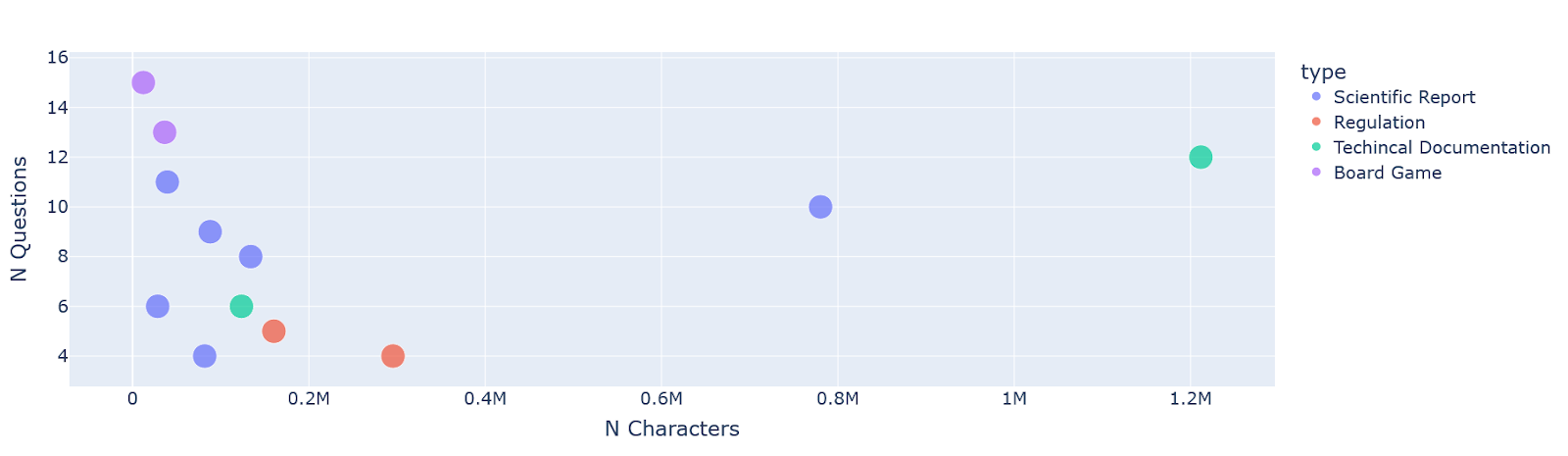
We manually collected a small set of questions (~100) on a diverse set of documents, including board game rule books, scientific papers and reports, regulatory documents, and technical documentation.
We included boolean, numeric and multi-choice questions across documents with varying length and structure.
This isn’t meant to be a rigorous research benchmark but rather an experimental approach to see how well language models handle structured documents in real-world question answering.
Comparison of existing methods
- Full Context Window
The model is fed with the entire document, alongside the question. All the information required to answer the question is available, but the model needs to process a lot of unnecessary information.
This method is limited by the length of the context window. From the set of open-source models that can run on accessible hardware (i.e. Google Colab: 13GB CPU RAM and 1 Nvidia T4) the vast majority couldn’t fit several of the documents used in the benchmark.
- Retrieval Augmented Generation (RAG)
The model is fed with chunks of the document, alongside the question. Whether the chunks contain enough information to answer the question depends on the RAG system.
This method is heavily dependent on the hyperparameters chosen for the different components (chunking, embedding, retrieving, etc.).
You can find out more about how a RAG system works here, and a collection of open-source RAG implementations using many different techniques here.
For our benchmark runs, we opted for the RAGatouille implementation due to its balance between ease of use and performance (and because it has an awesome name).
Models
We ran each of the methods using 2 different models:
We picked this model to represent the large closed-source models available via APIs. It has one of the largest context windows currently available via a (limited) free API, which makes it a great choice to evaluate the Full Context method.
We picked this model to represent the smaller open-source models that can run on accessible hardware (i.e. Google Colab). It has a reasonably long context window for a model of its size but, as shown in the results below, not enough to fit many of the documents included in the benchmark.
Results
In addition to the methods described above, we also evaluated the models in a “Perfect Context” setting, where the models were fed with a manually selected section. This is just used to provide a ceiling performance, as the solution is not applicable in a real world setting.

In the “Full Context” setting, the accuracy of the open-source model (Qwen2.5-7B-Instruct) is much lower because many of the documents didn’t fit the context length and thus the model collapsed.
Despite being able to fit all the documents, the closed-source model (Gemini 2.0 Flash) still shows a small room for improvement with respect to the “Perfect Context”.
Overall, the results show that there is a significant gap between the best available solution (Full Context using API models) and the one that fulfills the principles we use to build Blueprints (RAG using Local models).
Therefore we wanted to see if there was an alternative open-source and local/friendly approach.
Blueprint with a simple workflow as an alternative to RAG
There is already a wide variety of improvements on top of a basic RAG system, like agentic RAG, multi-agent RAG, etc. However, all of the proposed improvements significantly increase the complexity by introducing additional moving parts to configure.
Searching for alternatives, we found the Roaming RAG post, which introduces the concept of an “assistant” that “roams” around a document to find the right section to retrieve.
The concept was appealing and we tried to implement a similar approach, with some modifications to match our Blueprints principles:
- Don’t rely on function calling. For simplicity and because most small LMs are not really capable of function calling, unless finetuned.
- Focus on local, open-source models instead of API calls to larger, closed-source models.
- Don’t limit the inputs to documents specifically designed for LMs, since it is not really feasible (today) to expect documents like board game rule books to be published in an LM-friendly format.
- Simplify the section preprocessing (we chose to not include the initial text of each section in our first version).
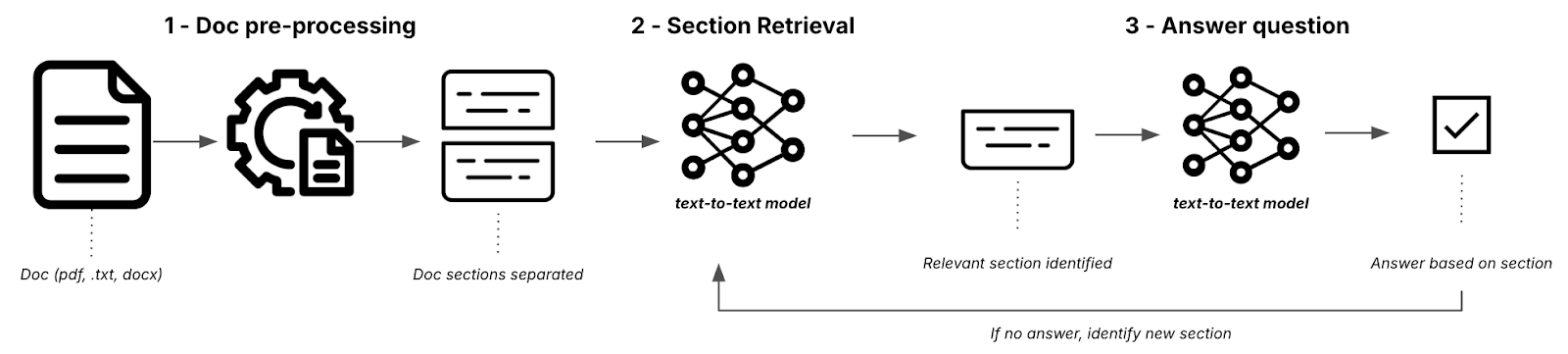
We decided to implement a simple workflow (following the terminology used in Building Effective Agents) and publish it in the Structured QA Blueprint:
Results
We tested our proposed method (named Find Retrieve Answer in the graph) with the same models.
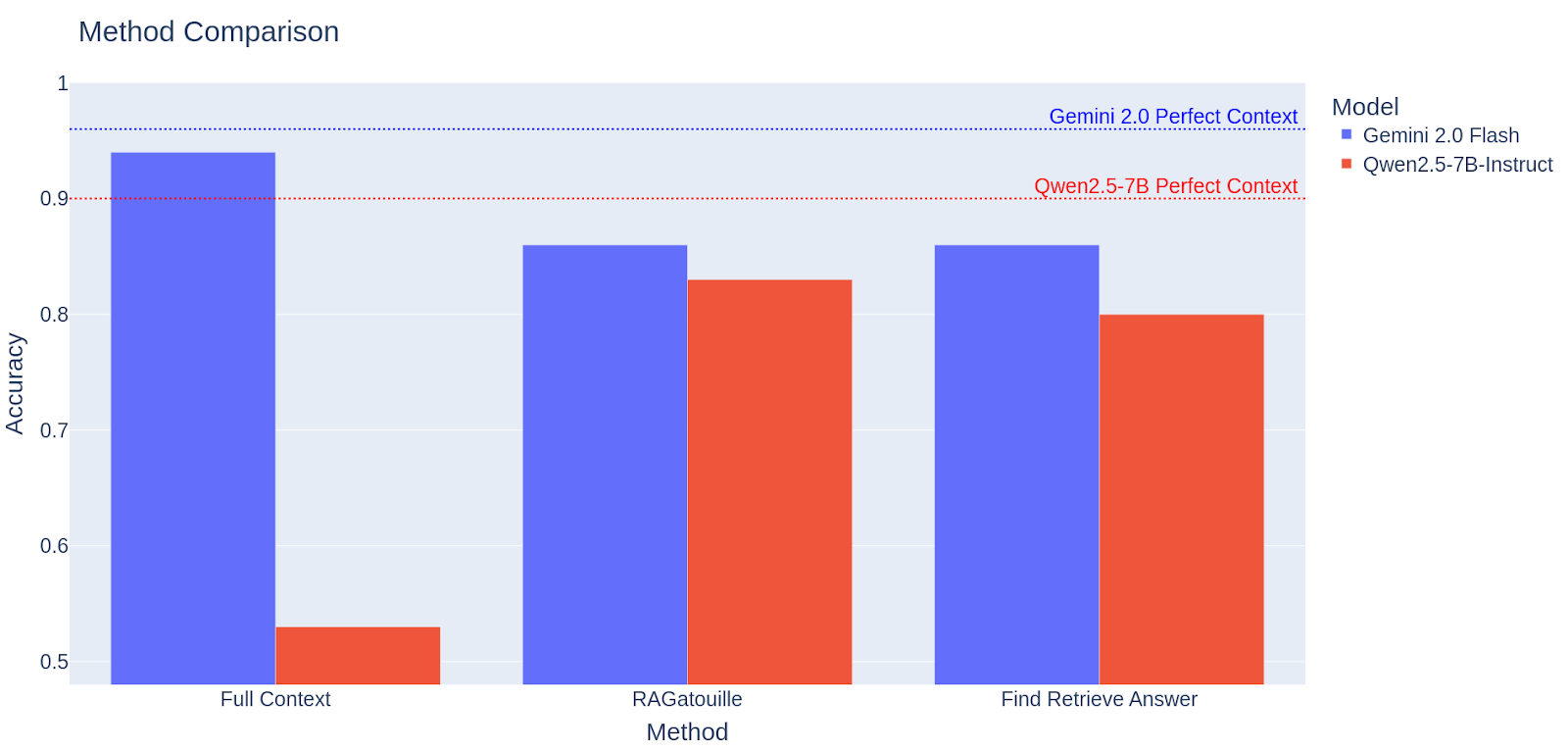
When using the API model (Gemini 2.0 Flash), our method achieves a performance on par with RAGatouille, while showing a small performance drop when using the Local model (Qwen2.5-7B-Instruct).
Analyzing the failures, we found that the preprocessing (where we extract the sections that give structure to the document) has a significant impact on the overall performance of our method. Failing to extract the true structure of the document makes the “Find” task a lot more difficult for the LM.
In these experiments we are using PyMuPDF4LLM, which seems to struggle processing visually complex layouts, like the ones used in board games rule books.

The drop between Gemini 2.0 and Qwen-2.5-7B also indicates that this method is more dependent on the LM performance than RAG, as it relies on it not only to answer the question but to find the right input context.
What about other models, like DeepSeek R1?
You can run the blueprint yourself using whatever model you prefer, as described in the Customization Guide. The 2 representative models were chosen as mere representatives of the API vs Local settings, because the main focus of our comparison were the methods.
We actually did a quick test using the distilled versions of DeepSeek R1 published by unsloth.ai as a potential default alternative to Qwen2.5-7B-Instruct for the local setting. We found that the model was frequently ignoring the instruction to “only answer based on the current information”, and was instead trying to reason the answer, causing more errors than the simpler model. You can find here an example of the collapsing response for a question with a very concise input context.
It might be possible that these failures are only present in the distilled versions and/or caused by the quantization used by unsloth.ai.
Conclusions
In the ecosystem rapidly growing around Language Models, sometimes it feels like increasing the complexity of the solution is the only path forward (i.e. from RAG to multi-agent RAG).
However, there are a lot of real world scenarios where you don’t need a solution capable of solving any task but rather something that fits your needs. A simple app for you and your friends to answer questions about a board game doesn't really need to be able to also plan your holidays and book you the flights.
Rather than jumping from RAG or Full-Context to more complex solutions, it’s worth considering how we can leverage domain specific knowledge, like the existing structure in documents to align AI retrieval with the way we naturally seek information.
While ‘Find, Retrieve, Answer’ shows a slight drop in performance compared to RAG, it shows promise as a local-friendly, simpler alternative, especially if preprocessing challenges can be refined and/or a more powerful model is used.
On that note, the Structured QA Blueprint is just a starting point.
We invite you to experiment with it: refine the document pre-processing, improve the prompt, or explore other enhancements. Open an issue, fork the repo and extend it, and share what you’ve managed to build. We’d love to feature your improvements on the Blueprint’s Hub page.



