
Towards Truly Multilingual AI: Breaking English Dominance


At the TAUS Massively Multilingual AI conference in Rome, I had the honor of moderating a panel on Multilingual AI provocatively titled “No English Please - How to move towards truly multilingual AI”. In this panel, we explored the pressing need for AI to transcend linguistic barriers and embrace global diversity. Here, I want to share a deeper dive into the critical issues we discussed, the innovative solutions our panelists are pioneering, and my perspective on the path forward for achieving a truly multilingual AI future 🚀.
Introduction to Multilingual AI
In business, tech, and academia, English has long been the dominant language, creating barriers for non-native English speakers. Ironically (or not), this dominance follows a centuries-old historical trend of using the language of the current dominant power, the way French once held sway as the international language of diplomacy and culture. (Perhaps it's high time for a shift to Portuguese, a language that I hold dear as a bi-national French and Portuguese individual 😉. Kidding!) More seriously, this language dominance limits people’s access (by everything being in English) but also perpetuates biases because of how the dominant language may ignore the diversity of other languages and cultures. To build a more inclusive digital future, where everyone can interact with machines, regardless of their language, we must address these challenges and develop truly multilingual AI systems.
The prevalence of English in technology and academia restricts non-English speakers, who often have to face the dual challenge of mastering both programming and a foreign language – even though expertise in science and technology is not inherently tied to English language proficiency. This issue is particularly pronounced in AI research and publishing, where most models and datasets are created predominantly in English, thus highlighting the need for AI models that operate effectively across multiple languages.
By developing multilingual AI models, we can ensure that non-English speakers can contribute to AI research and publications, access AI-driven tools, and benefit from AI advancements. Some of these benefits are:
- Inclusive Research and Collaboration: Multilingual AI models break down language barriers, allowing researchers from diverse linguistic backgrounds to access and understand AI research published in different languages. This inclusivity fosters global collaboration and knowledge sharing by making research accessible to a broader audience. Additionally, these models enable non-English-speaking researchers to publish their work in their native languages, ensuring that valuable research is not overlooked due to language constraints.
- Improved Access to AI Tools: Localized AI-driven tools and applications, designed to support multiple languages, become accessible to a wider audience, allowing non-English speakers to effectively utilize these tools in fields like education, healthcare, and technology. Providing AI tools in multiple languages enhances user experience and ensures seamless interaction with technology, thereby boosting productivity and engagement.
- Economic and Social Development: Localized AI applications can drive economic growth by enabling local businesses to reach a broader audience and improve their services, which can be particularly impactful in emerging markets. Furthermore, access to AI technologies in native languages empowers individuals and communities, fostering innovation and problem-solving at the grassroots level.
These benefits show that developing multilingual AI models is not just a technical necessity but a fundamental step towards an inclusive and equitable global AI landscape.
Real-World Examples and Shifts
At the TAUS Massively Multilingual AI conference in Rome, during my introductory talk, I highlighted the stark contrast between the most spoken languages in the world and their representation online:
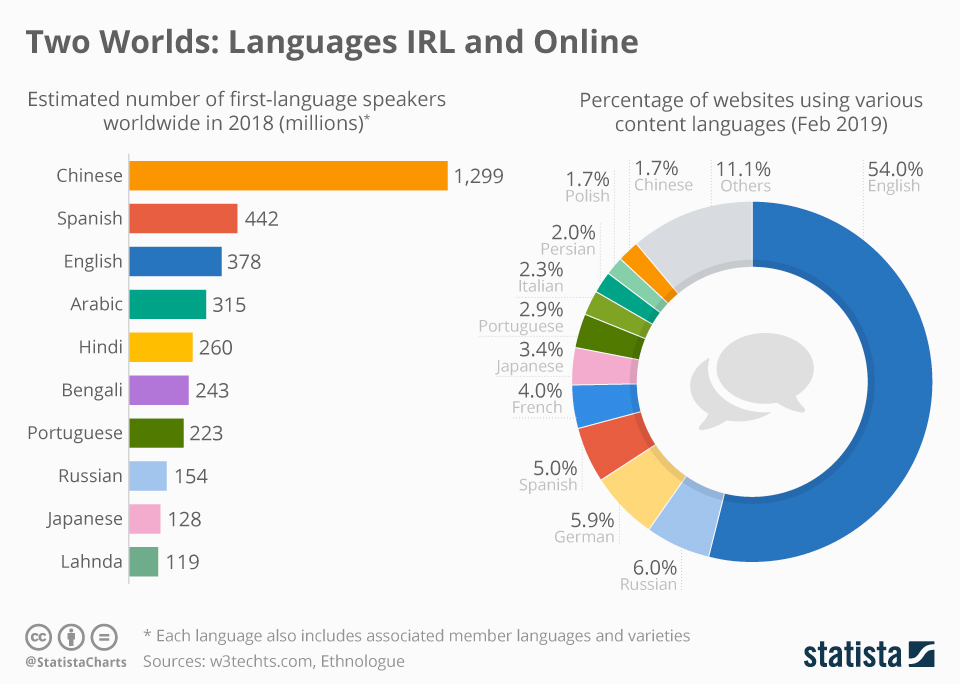
For instance, languages like Mandarin and Spanish are among the most spoken globally but their digital presence is disproportionately low compared to that of English. This issue is critical because the most performant large language models (LLMs) today have been trained on data largely crawled from the web, which is also predominantly in English, resulting in biases that not only limits the models' utility for non-English speakers but also fails to capture the cultural and linguistic nuances of other languages. Add to this the fact that the lack of diverse language data in training sets results in AI systems that do not understand or accurately process non-English languages, leading to subpar performance and reinforcing the dominance of English. In essence, we are using English datasets to train English models that aim to ‘understand the whole world’.
This discrepancy underscores the urgent need for more inclusive datasets that reflect the linguistic diversity of the real world. Without such data, AI models will continue to perpetuate the dominance of the most represented languages, failing to serve the broader global community effectively. Research by Bender et al. (2021) highlights the limitations of current datasets and the risks of neglecting linguistic diversity in AI models. Similarly, the work by Joshi et al. (2020) emphasizes the 'Linguistic Data Gap' in NLP and the importance of developing models that cater to a wider range of languages. A more recent study by Samardzic et al. (2024) reveals that the vast majority of the world's over 7000 languages are underrepresented in language technologies and NLP applications, leading to systemic biases and a lack of inclusivity in AI solutions. By creating more inclusive datasets, we can develop AI systems that more effectively serve all linguistic communities.
The panel I moderated featured experts who are pioneering projects to make AI more inclusive:
Gina Moape from Mozilla’s Common Voice, a publicly available, crowdsourced, and open-source dataset of voices around the world powered by the voices of volunteer contributors around the world.
Gina emphasized the importance of language diversity in AI and discussed how Common Voice is working towards this multilingual objective in the voice technology space. Common Voice is an initiative by Mozilla that aims to create an open-source database of voices and their transcription to improve speech recognition technology. It addresses the challenges of data scarcity, the need for inclusive and representative language data, and the benefits of a community-driven approach, allowing users to donate their voices to build diverse datasets.
Lucie Gianola from the French Ministry of Culture, ALT-EDIC Project, a European Commission project which aims to develop a common European infrastructure in Language Technologies, focusing particularly on Large Language Models.
Lucie discussed the role of governments in promoting linguistic diversity in AI and technology. She elaborated on the ALT-EDIC project, which aims to increase the availability of European language data, and stressed the importance of viewing AI and language technologies from a cultural perspective.
Kareem Darwish from aiXplain, a no-code platform that makes building tailored AI solutions easier and faster for businesses across all domains.
Kareem and his team introduced a solution that uses translation as a pivot to enable users to interact with LLMs in their native language. Karim discussed the longer-term goals of addressing data scarcity and cultural awareness in multilingual AI, highlighting the importance of overcoming language bias.
Christian Federmann from Microsoft shared insights into Microsoft's efforts to integrate nearly 100 new languages into their AI models. He discussed the challenges of preserving each language’s unique cultural flavor and the importance of creating truly multilingual AI systems that go beyond English-centric data and methods. His team at Microsoft has been actively involved in developing and releasing various datasets and tools, such as the Microsoft Speech Language Translation Corpus and contributions to the GEMBA metric for evaluating translation quality, which significantly aid in these multilingual efforts.
Proposed Solutions
These experts and their teams are raising awareness and criticizing the status quo, and at the same time actively contributing in their own ways to address the existing deficits of multilingual AI:
- Common Voice is crowdsourcing voice data in numerous languages to build more inclusive voice technology.
- The ALT-EDIC project is increasing the availability of European language data.
- aiXplain is using translation as a bridge to enable interaction with LLMs in various native languages.
- Microsoft is expanding the number of languages its AI models support, working to preserve cultural nuances in the process.
Pivot Language Bias in Multilingual AI
Despite advancements, English remains the core pivot language of many AI models, which also introduces systemic biases. This mirrors the Translation and Localization industry's historical use of English as a pivot language – a bridge language used to translate between two less common languages. For example, translating from Japanese to French might involve translating Japanese to English first, and only then English to French. Both fields rely heavily on English due to its vast data availability and established infrastructure.
However, this reliance creates biases and limits the representation of diverse languages and cultures. True multilingualism in AI requires more than just diverse language inputs and outputs; AI systems must accurately interact with users across different cultures and languages, ensuring accessibility and utility for all.
In the Translation industry, using English as a pivot language often results in translation inaccuracies and the loss of cultural nuances. For example, idiomatic expressions or cultural references unique to the source language may be lost or mistranslated when funneled through English. A concrete example is the misinterpretation of certain Japanese honorifics and cultural nuances when translated to English before being translated to another language, which can result in the final translation being less respectful or less culturally appropriate.
Similarly, in large language models, models trained predominantly on English data can misinterpret or overlook nuances in other cultures and languages. This can lead to AI applications that do not perform well for speakers of less-represented languages, thereby reinforcing linguistic and cultural inequalities. The Translation and Localization industry's adaptation to MT disruptions in the 1980s—balancing automation with human expertise—offers valuable lessons.
Professionals demonstrated resilience and innovation, emphasizing the importance of cultural sensitivity and quality. By learning from these experiences, we can better address the biases and limitations in AI, fostering more inclusive and accurate multilingual systems.
Learning from the Translation and Localization Industry
The Translation and Localization Industry offers valuable insights. It is not the industry’s first rodeo with respect to AI 🐴; it has already experienced significant disruption with the emergence of Machine Translation (MT) but has adapted pragmatically. Professionals in this field have demonstrated resilience and innovation, providing a blueprint for developing multilingual AI and adapting to the changes brought by generative AI today. Here are some specific insights and blueprints that can be drawn:
Ethical Considerations: Addressing ethical issues such as data privacy, consent, and fair representation has been integral to the industry. Applying these ethical standards to AI data collection and model training can enhance trust and acceptance.
Resilience and Innovation: The industry's ability to remain resilient and innovate in the face of disruption provides a blueprint for addressing current challenges in AI. Emphasizing flexibility, continuous learning, and innovation can help navigate the rapidly evolving AI landscape (Pym, 2023). Practices such as continuous professional development and adopting new technologies have been key to this resilience.
Scalability: The localization industry has managed to scale its operations globally while maintaining quality. Lessons on scaling infrastructure, managing diverse datasets, and ensuring consistent performance can guide the development of multilingual AI systems. Techniques such as cloud-based translation management systems and automated workflows can be particularly insightful (Gui, 2022).
User Feedback Loops: Incorporating continuous feedback from users has been crucial in improving MT systems. fostering a more cohesive and efficient ecosystem. Similarly, establishing robust feedback loops for AI models can help refine performance and adapt to evolving linguistic and cultural contexts (Banerjee & Lavie, 2005).
Collaboration and Standards: The industry has established collaborative frameworks and standards, such as the XLIFF (XML Localization Interchange File Format), which facilitate seamless integration and interoperability (Savourel, 2001). Developing similar standards around multilingual generative AI can enhance data sharing and model interoperability, fostering a more cohesive and efficient ecosystem.
Cultural Adaptation: Localization professionals have developed strategies to handle cultural nuances, ensuring that content resonates with diverse audiences. Techniques such as transcreation, which involves adapting content creatively to suit the target culture, can be particularly useful. AI models can learn from these practices to better understand and generate culturally appropriate outputs (Pedersen, 2005; Díaz-Millón & Olvera-Lobo, 2021).
Quality Assurance Processes: Implementing rigorous quality assurance measures, such as the Dynamic Quality Framework (DQF) and Multidimensional Quality Metrics (MQM), helps maintain high standards despite the use of automated tools. DQF provides a set of standardized metrics for evaluating translation quality, while MQM offers a flexible framework for assessing various aspects of translation quality. These processes can be adapted to multilingual AI to ensure models are evaluated and refined effectively.
Hybrid Approaches: The industry has successfully integrated MT with human expertise to maintain quality and cultural relevance. For instance, post-editing machine-translated content ensures accuracy while benefiting from automation's speed (Garcia, 2010; O’Brien, 2012). This approach allows for the rapid processing of large volumes of text while ensuring that cultural nuances and context are preserved .
By leveraging these insights and blueprints, the development of multilingual AI can be more effective, ensuring that it is not only technologically advanced but also culturally sensitive and ethically sound. This balanced approach will help create AI systems that truly serve a global audience.
Technical Considerations for Multilingual AI
Creating a truly multilingual AI involves various technical considerations, such as training models on diverse datasets that include multiple languages. This process is crucial to ensure that AI systems can accurately understand and generate text across various linguistic and cultural contexts.
Leveraging multilingual pre-trained models can significantly improve performance across languages. Some notable models include:
Multilingual T5 (mT5): Based on the T5 model, mT5 is pre-trained on the multilingual Common Crawl corpus covering 101 languages. It performs well on translation, summarization, and other NLP tasks (Xue et al., 2020). For more information on model selection for summarization models, read our previous post.
XLM-R (Cross-lingual Language Model - RoBERTa): This model extends the capabilities of mBERT by being trained on a much larger dataset, including more than 100 languages. XLM-R achieves state-of-the-art performance on several cross-lingual benchmarks (Conneau et al., 2020).
mBERT (Multilingual BERT): This model is a multilingual variant of BERT (Bidirectional Encoder Representations from Transformers) that has been trained on the top 104 languages with the largest Wikipedias. It captures cross-lingual context, making it effective for various multilingual tasks (Devlin et al., 2018).
Recent research emphasizes the importance of this approach for more inclusive and effective AI systems. For example, the surveys by Huang et al. (2023) and by Qin et al. (2024) highlight various multilingual LLMs, including models like mT5 and BLOOM, which are designed to handle multiple languages simultaneously. These models facilitate knowledge transfer from high-resource to low-resource languages, improving overall language model performance and inclusivity.
Another key aspect is the evaluation methods used to assess AI models. Traditional metrics like BLEU (Bilingual Evaluation Understudy) (Papineni et al., 2002) are commonly used for evaluating machine translation. BLEU scores are based on the precision of n-grams (contiguous sequences of n items from a given sample of text or speech) and measure how many words in the translated text match a reference translation.
However, BLEU has limitations, particularly in capturing linguistic diversity and cultural nuances. To address these gaps, other metrics like chrF (Popović, 2015) and TER (Translation Edit Rate) (Snover et al., 2006) are used. chrF is based on character n-grams, which makes it more adaptable to morphologically rich languages, while TER measures the number of edits required to change a hypothesis translation into one of the references, providing a more intuitive assessment of translation quality.
Evaluating these models on specific tasks is also essential. The evaluation harness developed by EleutherAI provides a framework for assessing language models on diverse tasks, including those specific to multilingual models (EleutherAI, 2023). This task-first approach ensures that models are tested in realistic scenarios that reflect their intended use cases.
For example, evaluating a model's performance on summarization tasks in multiple languages can reveal its ability to maintain accuracy and context across linguistic boundaries. Moreover, understanding when to use multilingual models versus language-specific models is crucial. For instance, if input documents are in French and a summary is required in French, a French-trained model might be more effective. However, if the task involves translating or generating content that spans multiple languages, a multilingual model would be advantageous.
Our platform at Mozilla.ai is being designed to facilitate these evaluations and offer ways to ensure the best models are knowingly selected for people’s specific use cases. By incorporating comprehensive evaluation metrics, we support the development of AI systems that are not only technically robust but also culturally sensitive and inclusive.
Connecting the Dots
To understand the broader implications and efforts toward creating a truly inclusive and open AI ecosystem, I invite you to read about our discussions at the Open Dataset Convening by Mozilla and EleutherAI. This event complements our goals by focusing on transparency and inclusivity in AI data practices. We discussed initiatives led by EleutherAI and Pleias, which are pioneering efforts in creating openly licensed LLM training datasets. Together, these initiatives represent a holistic approach to democratizing AI, ensuring it is accessible, transparent, and inclusive for all. So, dive in and discover how we're working to make AI as diverse as the languages we speak—one dataset and one evaluation at a time! 😅💪



