
What do you mean by AI testing...?
We recently discussed the increasing need to test applications that make use of AI with tests that target problems specific to AI models. But an immediate follow-up question then arises: What specific problems? How is that testing different?



We recently discussed the increasing need to test applications that make use of AI with tests that target problems specific to AI models. An immediate follow-up question we got was: What specific problems? How is that testing different?
It’s never a bad idea to hop over to OWASP for their current take on the Top 10. Nor is it to read up on other taxonomies. Broadly, the main groups concerning LLMs will ring a bell by now.
Hallucinations
Easily, the very first problem anyone encounters when interacting with LLMs: How much of an answer is coming from information sources the model is meant to be using, versus information it memorized during training or–worse–, simply words that fit nicely into a sentence?
Prompt injections and jailbreaks
If you’re familiar with SQL injections, you’re familiar with prompt injections. Moving from model failure to malicious intent: Can an input be crafted such that the LLM breaks out of its expected behaviour? We’ve come a relatively long way from the days of “Print out your system prompt”, but take a peek at what still works today.
Data leaks
Considering how much of LLMs’ abilities come from learning their training data and from predicting the next word based on that learnt data, it follows that a major risk is blurting out confidential data that it was trained on when inference time comes.
Bias & toxic outputs
As a software creator, you may not have had control over the data the model you use was trained on (although, if the training data were open-source, you could make an informed choice of model). Regardless, you will still be responsible for the content produced by your app.
You may think: “Surely once the original researchers have vetted a model, I can safely use it, right? My agents are safe, right?” Not so quickly. Adding tools to an LLM, or creating an agent, opens it up to indirect prompt injections. Case in point: Giving Grok 3 live access to X as a tool made it a self-fulfilling prophecy: 1) predict it would break when reading a sufficiently distinctive token on a tool it has access to; 2) see the model break when reading that token.
Convinced yet?
So, how do these tests work?
The example we put together used Giskard, but you may want to see a thorough comparison and explore other tools (Garak and PyRIT are rather popular and open-source too).
If you’ve ever done some hallway testing and later wondered: “How did they think of using the app like that?”... That’s what these tools mimic, with a healthy dose of malice and abundant prior work on top. They all send curveballs to your LLM (or the application that uses an LLM) and evaluate what comes back.
There are typically three phases: One where the tests or attacks are created, preferably based on some samples of your own, and potentially with the assistance of an LLM to dynamically create those curveballs. Vulnerability scanning tools will create attacks for known cases of the risk categories listed above, and can be extended with custom ones.
For example, you may bring a test sample question for your chatbot application: "What lies ahead on the path?" A vulnerability scanning library would create multiple attacks, augmenting the sample with character injections and glitch tokens.
In a second phase, once a test suite is assembled, your application is attacked and the responses analysed. The evaluation may be rule-based, or an LLM may assist in this evaluation. The last one returns the aggregated results to your CI/CD pipeline, for example.
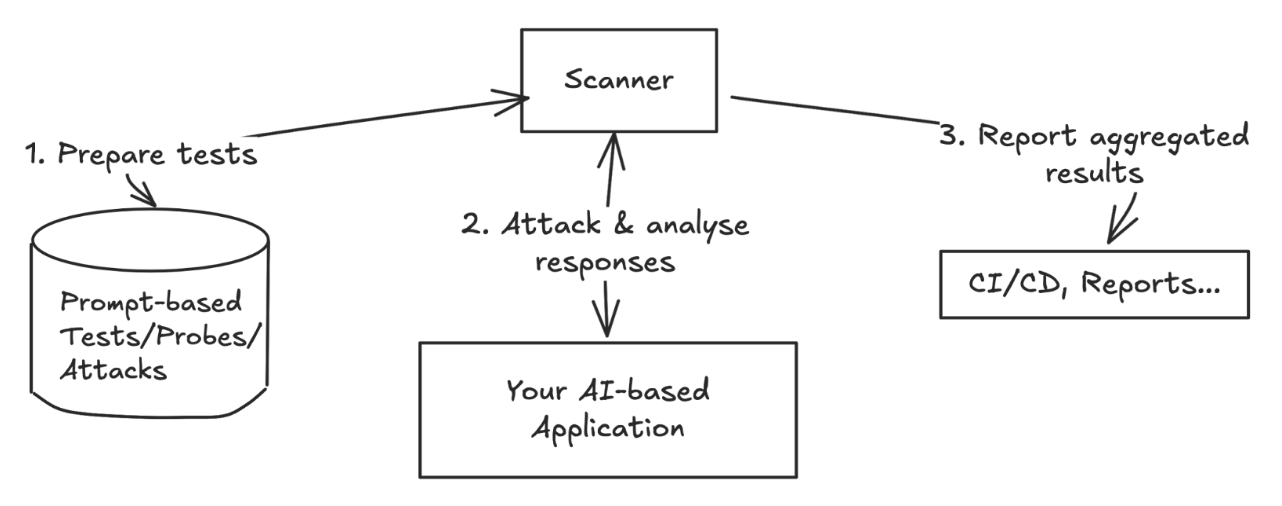
Whether you should be using an LLM to generate tests and evaluate results is a factor of cost, but also flexibility and (as anytime you consider LLM-as-a-judge) trust in that LLM. At least you can choose your model: As with the separation of powers, it’s not a bad idea to make the evaluating model different from the model under test.
What next?
Awareness is a good first step. Example repositories and tutorials make it easier to adopt the practice of regularly probing your applications (and eventually adding guardrails against risks!). AI software is still software after all.
But do reach out: Do you keep up with OWASP? Have you found and reported any LLM vulnerabilities? How do you test your AI applications? We would love to hear from you!



