
Local LLM-as-judge evaluation with lm-buddy, Prometheus and llamafile


In the bustling AI news cycle, where new models are unveiled at every turn, cost and evaluation don’t come up as frequently but are crucial to both developers and businesses in their use of AI systems. It is well known that LLMs are extremely costly to pre-train; but closed source LLMs such as OpenAI's are also very costly to use.
Evaluation is critical not only to understand how well a model works but also to understand which model works best for your scenario. Evaluating models can also be costly, especially when LLMs are actively used to evaluate other models as in the LLM-as-Judge case. And while techniques to scale inference could also be applied to LLM judges, there does not seem to be a lot of interest in this direction.
This post examines how different software components came together to allow LLM-as-judge evaluation without the need for expensive GPUs. All the components were built with and chosen for their user control, open source nature, and interoperability.
These include Prometheus, an open-source model for LLM-as-judge evaluation; lm-buddy, the tool we developed and open-sourced at mzai to scale our own fine-tuning and evaluation tasks; and llamafile, a Mozilla Innovation project that brings LLMs into single, portable files. I will show how these components can work together to evaluate LLMs on cheap(er) hardware, and how we assessed the evaluators’ performance to make informed choices about them.
An open toolkit
One feature I particularly like in Firefox is that when one types “moz://a” as a URL in the address bar they are automatically redirected to Mozilla’s manifesto. Mozilla was born in and of open-source ideals, and its manifesto talks about the principles of control over AI algorithms and their own experiences. This becomes particularly important in a market currently dominated by closed, AI-as-a-Service platforms.
The manifesto resonates with me and reminds me of a personal exercise I did just a short time before joining mozilla.ai: reading Mozilla’s principles in the light of a more modern Internet, one increasingly affected by the use of AI-powered algorithms.
If we substitute “the Internet” for “AI algorithms and/or frameworks”, the principles in Mozilla’s manifesto are still extremely relevant.
For example, we can paraphrase principles 5 to 7:
- individuals should have the ability to shape AI algorithms and their own experiences using them (see e.g. the Prosocial Ranking Challenge effort)
- the effectiveness of AI frameworks depends upon interoperability, innovation, and decentralized participation
- free and open-source software promotes the development of AI as a public resource
If we focus on LLMs (which, remember, are just a subfield of AI), we can see how important these principles are in a market currently dominated by closed, centralized, AI-as-a-service platforms. It is so important, in fact, that we have already witnessed the emergence of more open alternatives flooding into the mainstream.
Even if the tech industry can’t agree on what open source AI means yet, new models with OS licenses are continuously being posted on HuggingFace. They all come with pre-trained weights, ready to be used as-is or fine-tuned for downstream tasks. Sometimes papers are published with details about model training and used data. However, very few models are shared with research and replicability in mind, providing training code, checkpoints, and training data. Some of these very few models are BLOOM, Pythia suite, TinyLlama, and Olmo.
On the enterprise-facing side, a similar trend is occurring with businesses preferring smaller, open, ad-hoc models over large, closed ones. A report by Sarah Wang and Shangda Xu (Andreessen Horowitz) showed that cost is just one of the reasons for this choice, and not even the most important one. Other reasons are control: businesses want both the guarantee that their data stays safely in their hands and the possibility of understanding why models behave the way they do; and customization: the ability to fine-tune models for specific use-cases.
Regarding fine-tuning, in their recent LoRA Bake Off presentation, Predibase engineers showed that small, open-source fine-tuned models can perform better than GPT4 on specific tasks. While GPT4 can be fine-tuned too (and this might change the status quo performance-wise), it’s the need for both control and customization that allows companies such as OpenPipe to raise funding with the claim of “replacing GPT-4 with your own fine-tuned models”.
Interoperability is not the only requirement for replacing a model with one another. We need to evaluate models to compare their performance, so we can choose the one that best fits our purpose.
LLM evaluation
One thing we experienced firsthand at mzai when working on evaluation tasks (both during the NeurIPS LLM Efficiency Challenge and for our internal use cases) is that there is often an important disparity between offline and online model performance (or, respectively, model and product performance as defined in this guide by Context.ai) such that the former is often not predictive of the latter.
Offline LLM evaluation is performed on models, using academic benchmarks and metrics which are recognized as being predictive of model performance on a given task (1). Online LLM evaluation is performed on LLM-based products, very often in a manual fashion on custom datasets, and is aimed at assessing the quality of responses in terms of metrics that are typically more product-specific, e.g. measures of hallucination, brand voice alignment, reactions to adversarial inputs.
This “offline-online disparity problem” is quite common in other fields. Funnily enough, it is very relevant in social network recommender systems, which some of the members of our team (including yours truly) hoped to have finally left behind when moving to the trustworthy AI field (add your favorite facepalm emoji here).
To address this problem, LLM as a judge methods aim to bridge the gap between online and offline evaluation by using another LLM model to evaluate the responses of your LLM application. The assumption is that, with proper training, they can be a better proxy to measure online performance than offline evaluations, while at the same time cheaper than running manual online evaluation.
As with many other LLM-based applications, there are different tools that rely on GPT4 for this. For example, this post by Goku Mohandas and Philipp Moritz at Anyscale documents a GPT4-based evaluation I particularly liked, thanks to its step-by-step nature, the presence of reference code, and extensive results.
Fortunately, alternatives to “GPT-4 as a Judge” that rely on open-source models are being made available. These seem to have comparable performance at a fraction of the price (2). Prometheus and Ragas are some examples that can be used to evaluate, respectively, LLM-based and RAG-based systems. In this post we will focus on the former.
Prometheus
Prometheus is a fully open-source LLM (released on HuggingFace with the Apache 2.0 license) that is on par with GPT-4's capabilities as an evaluator for long-form responses. It can be used to assess any given long-form text based on a customized score rubric provided by the user and experiments show a high Pearson correlation (0.897) with human evaluators. The paper presenting Prometheus was accepted at the Instruction Workshop @ NeurIPS 2023 and there is already a follow-up aimed at tackling Vision-Language models.
The picture below describes at a very high level how Prometheus scoring works:
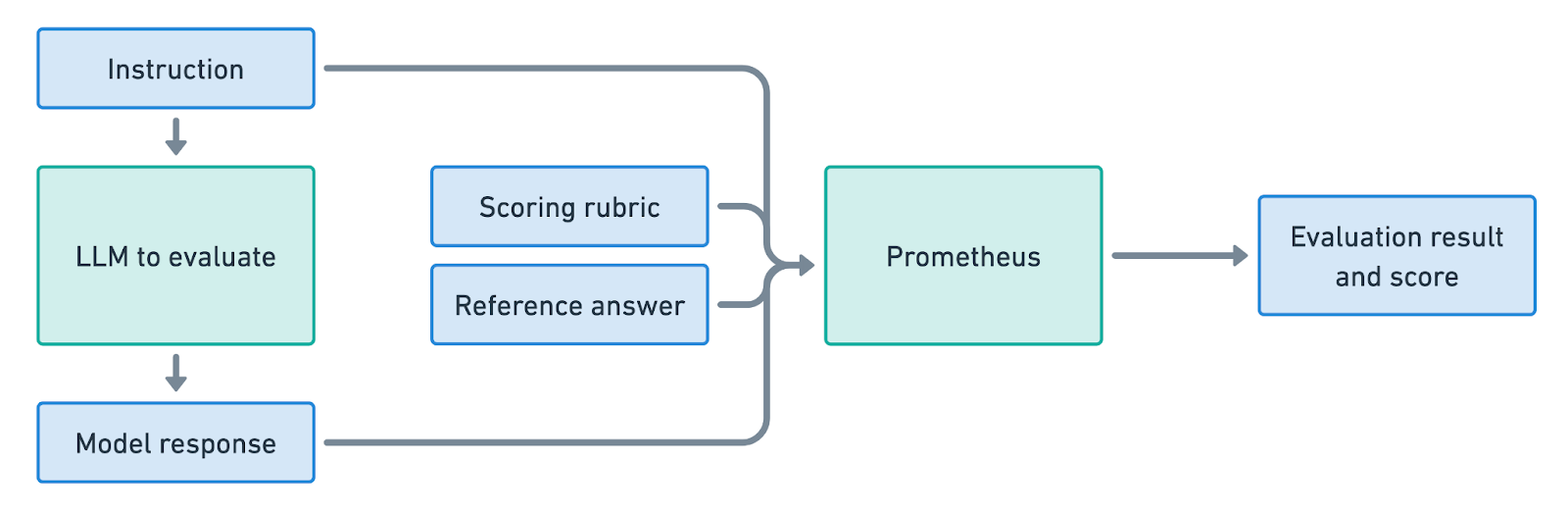
In practice, every prompt submitted to Prometheus is made of four parts: 1) the instruction provided to the model to be evaluated, 2) the model’s response, 3) a reference answer showing how an answer with the best score would look like, and 4) a custom scoring rubric which is used to describe the main aspects required for addressing the instruction.
The box below shows an example from the mt_bench dataset provided in the Prometheus repository. As the name suggests, this dataset has been built by relying on the MT Bench Human Judgements data, a collection of answers provided by six different models to a set of open-ended questions and evaluated by human experts.
When Prometheus receives such a prompt, its response will contain evaluation feedback (in natural language) for the provided response and a numerical score in the range specified by the rubric.
###Task Description:
An instruction (might include an Input inside it), a response to evaluate, a reference answer that gets a score of 5, and a score rubric representing a evaluation criteria are given.
1. Write a detailed feedback that assess the quality of the response strictly based on the given score rubric, not evaluating in general.
2. After writing a feedback, write a score that is an integer between 1 and 5. You should refer to the score rubric.
3. The output format should look as follows: \"Feedback: (write a feedback for criteria) [RESULT] (an integer number between 1 and 5)\"
4. Please do not generate any other opening, closing, and explanations.
###The instruction to evaluate:
Here is a previous dialogue between an assistant and an user. Generate a human preferable response by the assistant.
User: Which word does not belong with the others?
tyre, steering wheel, car, engine
Assistant:The word "tyre" does not belong with the others because it is a part of the car, while the others are components or features of the car.
User: Could you replace it with a word that belongs with the others?
Assistant:
###Response to evaluate:
Yes, a word that belongs with the others could be "brakes."
###Reference Answer (Score 5):
Yes, a word that could replace "car" to fit with the others could be "brakes." This is because brakes, like tyre, steering wheel, and engine, are all parts of a car.
###Score Rubrics:
[Does the response include a plausible example and provide a reasonable explanation?]
Score 1: The response does not include an example or explanation, or the example/explanation provided is not plausible or reasonable.
Score 2: The response includes an example but lacks an explanation, or the explanation does not adequately support the example provided.
Score 3: The response includes a plausible example and provides a somewhat reasonable explanation, but there may be minor discrepancies or areas of confusion.
Score 4: The response includes a plausible example and provides a mostly reasonable explanation, with only minor potential for confusion.
Score 5: The response includes a highly plausible example and provides a clear and thorough explanation, leaving no room for confusion.
###Feedback:
The Prometheus code, paper, and training data are available here. After installing the required dependencies and filling up the prompt template in the run.py file, one can run an example evaluation from the command line. Alternatively, full benchmark scripts are made available which rely on the model served via TGI.
Note that Prometheus is a fine-tuned version of the Llama-2-Chat-13B model, thus it is quite memory-hungry: it needs a GPU to work (a powerful one for the original model, which requires more than 70GB RAM) which has to be considered in addition to those allocated for the evaluated models. To address this limitation, we show how to run a quantized version of this model and evaluate its performance in terms of correlation with the output of the original one.
LM Buddy
During the NeurIPS LLM Efficiency Challenge it became clear that having a simple, scalable system for both fine-tuning and evaluation of LLMs was of paramount importance. The tools provided in the challenge by default (LitGPT for fine-tuning and HELM for eval) served their purpose for individual submissions. However, our experience with fine-tuning and evaluating many different models at the same time made clear some opportunities for improvement and generalization.
Specifically, we wanted to:
- Create a pipeline of jobs that could be run locally on a laptop as well as remotely on a cluster
- Provide experiment tracking features so that different tasks in the same experiment can share artifacts and configuration parameters, and logging that allows us to track artifact lineage
- Keep job specs simple and allow users to easily create new ones
- Have different components communicate through open or de facto standards
LM Buddy, available on GitHub, is the framework we’ve been building internally at mzai, and have open-sourced, to provide this exact set of features. In our path to give developers a platform to build and deploy specialized and trustworthy AI agents, this is a core component that we chose to share early and build in the open. It currently offers the ability to fine-tune and evaluate language models using abstractable jobs.
Despite still being in its early stages, the library already presents some useful features:
- An easy interface to jobs which is based on CLI commands and YAML-based configuration files
- input/output artifact tracking (currently relying on Weights & Biases)
- the ability to run jobs locally as well as easily scaling them on a remote Ray cluster
The package currently exposes two types of jobs:
- (i) fine-tuning jobs, which rely on HuggingFace models and training implementations, and Ray Train for compute scaling, and
- (ii) evaluation jobs, which can be scaled with Ray and currently rely on lm-evaluation-harness for offline evaluation and Prometheus and Ragas for LLM-as-judge
When inference is required, either for models to be evaluated or for LLM judges, we serve models using vLLM and make sure the libraries we use and develop support the OpenAI API (see e.g. this PR).
The Prometheus job on LM Buddy
Prometheus evaluation as an LM Buddy job reads an input dataset that contains prompts to be evaluated, sends those prompts to the LLM judge served via vLLM, and outputs another version of the dataset which is augmented with Prometheus’ feedback and scores. When working with the original Prometheus model, we allocate a single GPU for it and run the evaluation job from (possibly many) CPU-only machines (see figure below).
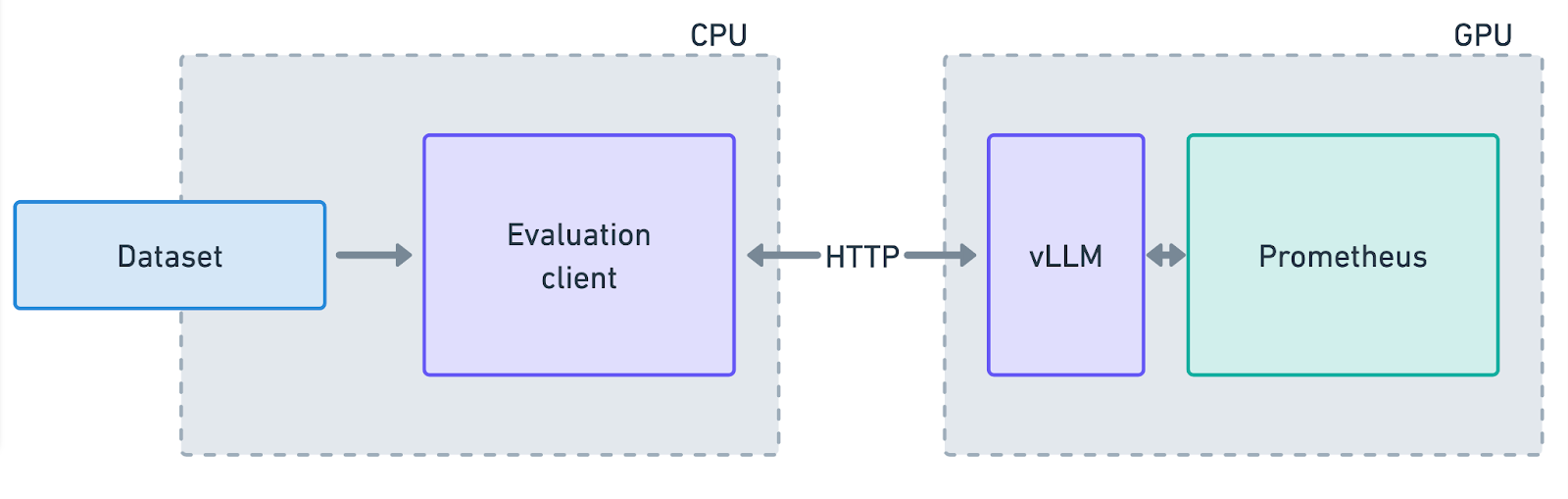
Details and examples for running a Prometheus evaluation with LM Buddy are provided in the tutorial you can find here. They involve:
- preparing an input dataset (or using one of those provided in the Prometheus repo),
- serving Prometheus via an OpenAI-compatible API (e.g. using vLLM),
- preparing a configuration file starting from this example,
- running the following:
python -m lm_buddy evaluate prometheus --config path/to/your/prometheus_config.yaml
While this worked nicely for our internal use cases, we realized that we were still requiring people to (i) have a GPU devoted to evaluation and (ii) configure and deploy the serving of a Prometheus model on their own. Wasn’t there a way to make this easier for end users?
llamafile
llamafile is a Mozilla Innovation Project initiative that “collapses all the complexity of a full-stack LLM chatbot down to a single file that runs on six operating systems”. It relies on two open-source projects: llama.cpp, aimed at running LLMs on consumer-grade hardware, and Cosmopolitan, which compiles C programs into polyglot executables that run on a wide variety of operating systems. While both Cosmopolitan and llama.cpp have been around for a while, they are a great example of how the whole is greater than the sum of its parts.
llamafile allows us to run models on our laptop from a single file: thanks to a simple Flask-based python middleware proxying llama.cpp’s own server, it can be accessed using an OpenAI-compatible API. And thanks to Justine Tunney’s recent improvements to matrix multiplication kernels for llamafile, prompt processing time has been dramatically reduced, reaching better performance than llama.cpp alone and ollama.
What this means for us is that (i) we can seamlessly substitute a vLLM-served Prometheus with its llamafile version and (ii) it is going to run on a wide variety of hardware setups.
Building the Prometheus llamafile
The llamafile github repo already provides various models for downloading, and HuggingFace just recently started officially supporting llamafile models. Before our experiments, there was no Prometheus model available in the llamafile format, so we had to build it ourselves. This boils down to (i) building llamafile, (ii) downloading Prometheus in GGUF format, and (iii) packaging everything together.
Step-by-step instructions are available below:
# (1) get llamafile
git clone https://github.com/Mozilla-Ocho/llamafile.git
cd llamafile
# (2) compile and install
make
make install
### NOTE: if the above does not work, install cosmocc and then
### use it to compile and install llamafile as follows:
# ---------------------------------------------------------------
# get cosmocc
mkdir -p .cosmocc/3.2.4
cd .cosmocc/3.2.4
wget https://cosmo.zip/pub/cosmocc/cosmocc.zip
unzip cosmocc.zip
cd ../..
# build llamafile
.cosmocc/3.2.4/bin/make
.cosmocc/3.2.4/bin/make install
# ---------------------------------------------------------------
# (3) download TheBloke's quantized version of prometheus
# NOTE: we are downloading the 5-bit version but you can choose the
# one that works best for you (see experiments below in this post)
mkdir prometheus
cd prometheus
curl -L -o prometheus-13b-v1.0.Q5_K_M.gguf https://huggingface.co/TheBloke/prometheus-13B-v1.0-GGUF/resolve/main/prometheus-13b-v1.0.Q5_K_M.gguf
# (4) convert the GGUF file in a llamafile
### Manual approach (more control over your llamafile configuration):
# (4a) create the `.args` file with arguments to pass llamafile when it is called
# (`...` at the end accounts for any additional parameters)
echo -n '''-m
prometheus-13b-v1.0.Q5_K_M.gguf
-c
0
...''' >.args
# (4b) copy llamafile to the current directory
cp /usr/local/bin/llamafile prometheus-13b-v1.0.Q5_K_M.llamafile
# (4c) use zipalign (part of llamafile tools) to merge and align
# the llamafile, the .gguf file and the .args
zipalign -j0 \
prometheus-13b-v1.0.Q5_K_M.llamafile \
prometheus-13b-v1.0.Q5_K_M.gguf \
.args
### Alternatively: automatic approach (one single command, no control over args)
llamafile-convert prometheus-13b-v1.0.Q5_K_M.gguf
# (5) aaand finally just run the llamafile!
./prometheus-13b-v1.0.Q5_K_M.llamafile
Using the Prometheus llamafile with LM Buddy
Once the Prometheus llamafile is executed, it will load the model into memory and open a browser tab containing the chat UI. You can test everything’s working by starting a chat (after all, the Prometheus model is just a fine-tuned version of Llama).
As our lm-buddy job requires Prometheus to be served using an OpenAI-compatible API, we can run the following to make llamafile compatible with it:
# add dependencies for the api_like_OAI.py script
pip install flask requests
# from the llamafile repo main directory:
cd llama.cpp/server
python api_like_OAI.py
This starts a local server listening to http://127.0.0.1:8081. Now you just need to set prometheus.inference.url to this URL to run evaluations using the llamafile version of Prometheus.
Experimental Results
Impact of quantization on quality performance. As with every other model published in GGUF format by TheBloke, their Prometheus page on HuggingFace has a Provided files section offering different variants of the model according to their quantization level.
Quantization is a technique that reduces both memory requirements and computational costs by representing model weights and activations with a lower-precision data type (e.g. from 32-bit floating point numbers to 8-bit integers). The fewer bits one uses, the smaller the model, which means it will run on cheaper hardware; but at the same time it will be worse at approximating the original model weights and this will affect its overall quality.
TheBloke’s tables are helpful in this respect as they show, together with the number of bits used for quantization and the overall model size, a “use case” column providing a high-level description of its quality. To provide more interpretable results for our specific use case, we decided to measure how much models at different levels of quantization agree with the original one’s scoring.
We took the Vicuna benchmark and ran the evaluation with lm-buddy three times, using both a vLLM-served Prometheus and local llamafiles with the quantized model (at 2, 5, and 8 bits), then calculated the Pearson correlation coefficient (PCC) of their average scores. Correlation values are in the [-1, 1] interval and the higher it is the better. The table below shows our results:
A few things are notable:
- the PCC (GPT4) column shows PCC with scores generated by GPT4. Results are consistent with those in the Prometheus paper (see Table 4, first column), where the PCC between Prometheus and GPT4 was 0.466; interestingly, Q8 has a higher correlation with GPT4 than the original model
- the PCC (orig) column shows PCC with scores generated by the original Prometheus model. Note that the correlation value of the original model with itself (first row) is not 1! The reason is that we decided not to compare the scores against themselves, but with a different set obtained in another evaluation run. We did this to emphasize that results are stochastic, so when doing our evaluations we will always have to account for some variability
- as expected, the more bits we used for quantization the more the llamafile model is consistent with the original one, as shown by higher PCC values
- while the Q8 model has the highest similarity with the original one, Q5 still has a rather high PCC while requiring just 16GB of RAM (allowing us to run it e.g. on laptops and cheaper GPUs)
Consistency with our own manual annotation. We decided to test Prometheus and llamafile on a simple, custom use-case. We tested different models (including GPT4, GPT3.5, Mistral-7B, and Falcon) on a RAG scenario, generating model answers from a set of predefined questions and evaluating them both manually and with Prometheus, using a custom rubric and running both the original model and a llamafile version (based on prometheus-13b-v1.0.Q5_K_M.gguf).
Here are some notes about our results:
- the PCC between our manual annotations and the original Prometheus model is 0.73, showing there was overall agreement between our two evaluations
- the PCC between manual annotation and llamafile is 0.7, showing that overall the quantized model is quite in agreement with the original one. Consistently with this, the PCC between the original Prometheus model and its llamafile version is 0.9.
Evaluation speed and cost. We ran the same Vicuna benchmark using the original Prometheus model on a machine with an A100 GPU and a Prometheus llamafile based on prometheus-13b-v1.0.Q5_K_M.gguf on different architectures. The benchmark holds 320 prompts which are evaluated 3 times each, for a total of 960 HTTP requests to the model. The table below shows a performance comparison.
[*Note: we used Q2 model here, just to see if it would fit on the RTX 4000. Well, it does not :-) unless you choose to load just 35 out of the 40 layers into VRAM. This is ok -as speed is not dramatically affected- but the model output will likely be less reliable.]
The most important take-home message here is that the answer to the question “which is the most cost-effective model?” is not obvious. It needs to take into consideration different variables:
- absolute cost (i.e. not just price/hour, but also how many hours it will take to run a given evaluation job on that hardware, are relevant information)
- on-demand vs reserved vs bare-metal price (i.e. how many of these inferences do I have to run?) Depending on your needs, it might be way cheaper for you to get a GPU on-demand or buy a new Macbook
Conclusion
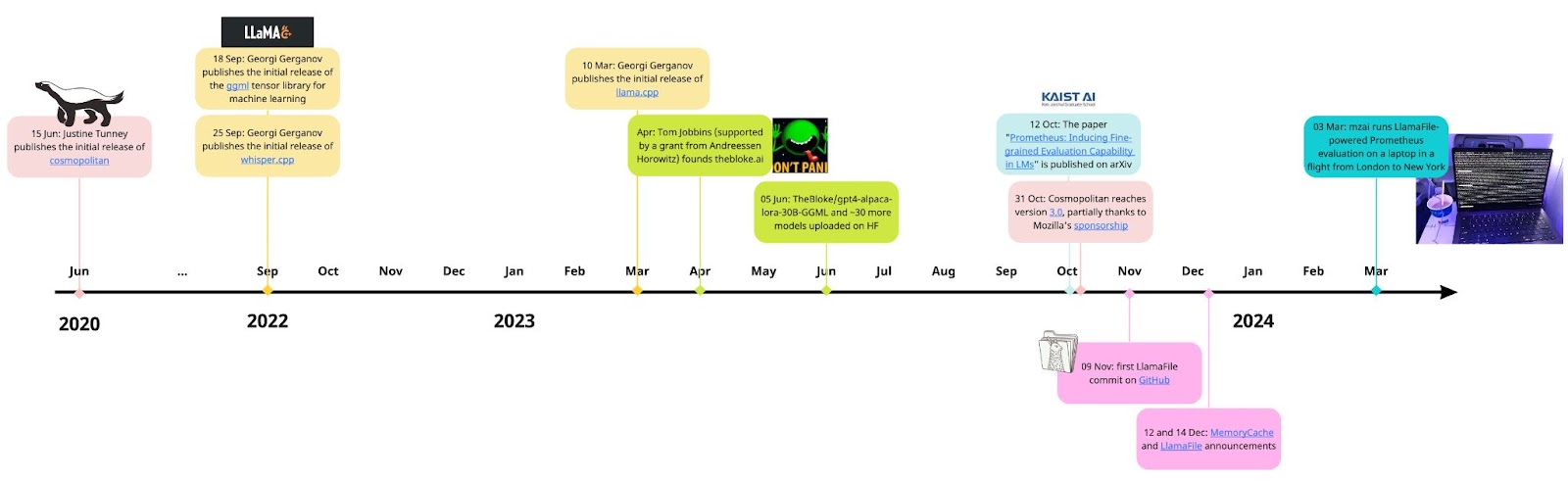
The rightmost image you can see in the timeline above depicts the eureka moment of the experiment you just read about. That excited me not much for the results I got (to be fair, my laptop’s battery died before we landed), but rather for the feeling of control it gave me: I did not have to rely on a third-party inference service or cloud GPU for doing LLM-as-judge evaluation.
Be aware that Prometheus is one of many LLM-as-judge approaches available, but more importantly that LLM-as-judge itself is not a “one size fits all” solution: we are still dealing with LLMs after all! Performance depends both on the quality of the provided rubrics and on the generalization capabilities of the models we use as judges. There is also the very important question of “Who Validates the Validators?”, which I only partially addressed here by testing how different models performed compared to some baselines. Still, while the kind of ML evaluation we can trust the most is still made by humans, it is important to showcase open, affordable proxies to manual eval that we can experiment with: either to make an informed decision about which model works best for a particular use case or to find the best trade-off between model quality and cost.
From a higher-level perspective, the local LLM-as-judge evaluation we described in this post results from linking together many projects developed in the open. The timeline in the figure above shows just the few projects we cited here, but they’re enough to show the secret sauce that made our effort possible: these projects were not just meant to be open-source, they were built with interoperability in mind. From building portable executables to defining a standard binary format for distributing LLMs, from sharing pre-quantized models to serving models with a common API, all of these efforts are meant to incentivize software modularity as well as human collaboration.
Acknowledgments
A huge thank you to Stephen Hood, Kate Silverstein, and Justine Tunney for both llamafile and their feedback, and to my team for building the bootstraps we can pull ourselves up by.
1. e.g. precision and accuracy on multiple-choice closed-ended questions, text-similarity metrics such as ROUGE, BLEU, or BERTScore for summarization, etc.
2. https://arxiv.org/pdf/2310.08491.pdf states that “evaluating four LLMs variants across four sizes (ranging from 7B to 65B) using GPT-4 on 1000 evaluation instances can cost over $2000”, a cost that can be prohibitive for an individual or even an academic institution. Assuming we can run ~300 evaluations per hour (see our experiments below), this would cost less than $30 using an on-demand A100 GPU with 40GB RAM.



