
llamafile Reloaded: What’s New in v0.10.0
llamafile 0.10.0 unifies portability and modern model features. Bundle weights, run multimodal models, and access tool calling and Anthropic Messages API support, all from a single executable.

Dad of 3564020356.org and two amazing kids. Interested in open applications of ML on federated systems. Trustworthy AI at moz://a.ai. Genetically a teacher, forever a student. At: @mala@fosstodon.org

llamafile 0.10.0 unifies portability and modern model features. Bundle weights, run multimodal models, and access tool calling and Anthropic Messages API support, all from a single executable.

Mozilla.ai joins Flower Hub as a launch partner with fed-phish-guard, a federated phishing detection project. The classifier trains across distributed clients and shares only model updates, allowing collaborative learning without centralizing browsing data.

Product Release
Mozilla.ai is adopting llamafile to advance open, local, privacy-first AI—and we’re inviting the community to help shape its future.

Product Release
mcpd is to agents what requirements.txt is to applications: a single config to declare, pin, and run the tools your agents need, consistently across local, CI, and production.

Technical Content
One of the main barriers to a wider adoption of open-source agents is the dependency on extra tools and frameworks that need to be installed before the agents can be run. In this post, we show how to write agents as HTML files, which can just be opened and run in a browser.

Technical Content
Generative AI models are highly sensitive to input phrasing. Even small changes to a prompt or switching between models can lead to different results. Adding to the complexity, LLMs often act as black-boxes, making it difficult to understand how specific prompts influence their behavior.
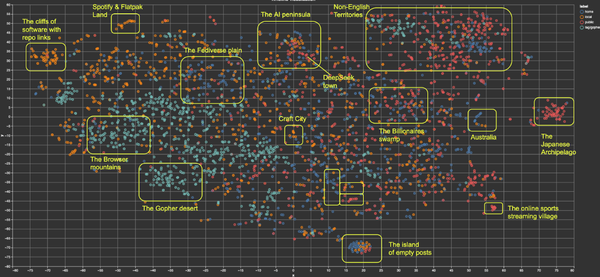
Technical Content
Timeline algorithms should be useful for people, not for companies. Their quality should not be evaluated in terms of how much time people spend on a platform, but rather in terms of how well they serve their users’ purposes.

Technical Content
New state-of-the-art models emerge every few weeks, making it hard to keep up, especially when testing and integrating them. In reality, many available models may already meet our needs. The key question isn’t “Which model is the best?” but rather, “What’s the smallest model that gets the job done?”

Technical Content
A typical user may be building a summarization application for their domain and wondering: “Do I need to go for a model as big as DeepSeek, or can I get away with a smaller model?”. This takes us to the key elements: Metrics, Models, and Datasets.

Technical Content
The behavior of ML models is often affected by randomness at different levels, from the initialization of model parameters to the dataset split into training and evaluation. Thus, predictions made by a model are potentially different every time you run it.

Technical Content
In the bustling AI news cycle, where new models are unveiled at every turn, cost and evaluation don’t come up as frequently but are crucial to both developers and businesses in their use of AI systems. It is well known that LLMs are extremely costly to pre-train; but closed