First Line of Defense for cq
cq helps coding agents share resolution paths and learn from past failures. We partnered with Lauren Mushro to bring VIBE✓ into cq and help review knowledge units before they enter shared memory.



At Mozilla.ai, we recently released cq, a way for agents to share experience-driven knowledge so they can stop repeating each other’s mistakes. cq is extremely easy to use. When a session with a coding agent has an error that the agent struggles to comprehend or identify, cq will call propose in the background to capture resolution paths for novel errors it encounters. Developers can also call /cq:reflect, which triggers the agent to summarize the context, look for similar errors faced by other agents in the knowledge store, identify the resolution paths, and then propose them to the user for approval. The amount of human friction in this process is minimal: a quick review of proposed knowledge units and the click of an approval button.
However, the sheer speed of this process exposes a key vulnerability: automation bias. This is the implicit human tendency to trust automated decisions more than our own judgment. Automation bias can result in API key leakage, PII exposure, and unintentional sharing of other sensitive session context. While /cq:reflect has instructions to remove this type of information, but the risk still remains, which is why we want users to take the review of knowledge units seriously.
To that end, we are introducing a new framework developed by Lauren Mushro, Human-Centered Design Lead, Responsible AI (RAI) at Bank of Montreal and RAI System Design Professor, to help with checking knowledge units before they enter your local store. VIBE✓ provides a set of criteria for both humans and agents to create a more robust knowledge unit generation and storage experience. Along with VIBE✓, developers utilize a checklist to analyze potential sociotechnical issues in the agent session that should be considered before /cq:reflect activates.
The Responsible AI community has enforced checklists for years. From the Deon by DrivenData to the AI Safety Benchmark Design Checklist, AI ethicists have long advocated for offloading the cognitive load of remembering every concern to an enumerated tracking system. Checklists like these are easy to implement and integrate into a developer’s workflow, and avoid the complex caveats that often come with traditional fairness, bias, and safety mitigations. These varied approaches inspired VIBE✓ to help vibe coders and traditional developers using AI coding agents to think through the potential issues that may arise from AI written code.
What is VIBE✓ [VIBE Check]?
VIBE✓ is pre-deployment accountability infrastructure. It reintroduces useful friction into the shipping process by asking human teams to document vulnerabilities, blind spots, and intention-impact gaps before a system goes live. Rather than treating responsibility as a post-hoc audit, VIBE✓ builds accountability into the development pipeline as a seam between building and shipping.
The framework takes its name from four documentation categories:
- Vulnerability: What and who becomes exposed through this code’s existence
- Intention versus Impact: The gap between what a system is trying to do and what it actually does
- Bias & Blind Spots: Known limitations in the agent’s training or assumptions in the code
- Edge Case Handling: Stress-testing the system before it meets users
The √ stands for the act of checking your work before committing.
VIBE✓ Framework in Action
Vulnerability documentation traces the architecture of exposure a system creates. For coding agents, this pushes developers to consider: what sensitive architecture, proprietary logic, or user data might become exposed or permanently logged if this agent’s resolution becomes available in the cq commons?
- NOTE: This portion of the framework should not be automated by an agentic workflow; it requires organic and contextual judgement by the developer team.
- Example documentation: [Agent X] successfully resolved a database connection timeout error. However, the proposed knowledge unit hardcodes a reference to an internal staging IP address and includes an authentication endpoint's specific retry logic. Saving this unit to a shared cq store creates a security vulnerability and exposes internal infrastructure routing.
Intention versus impact addresses the gap between what a system is designed to do and what it actually does. Development teams are asked to document intended goals, anticipated real-world outcomes, and the divergence between these two, specifically in cases where a system optimizes for measurable metrics at the expense of user welfare.
- NOTE: Like vulnerability, Intention vs. Impact requires deep human oversight.
- Example documentation:
Bias and Blindspots asks development teams to document known biases in training data, design assumptions, and system architecture, as well as acknowledging the limits and boundary of the team’s knowledge.
Teams should address:
- Demographic gaps in training or test data;
- Assumptions baked into feature design;
- Populations for whom the system was not designed or tested;
- Conditions under which system performance degrades.
Edge Case Handling
Before deploying a new knowledge unit into cq, teams should document how the proposed resolution handles inputs, users, or conditions outside its primary design parameters. Edge case documentation should address failure modes, escalation paths, and whether the system fails gracefully or catastrophically.
✓ [CHECK]
The last component of VIBE✓ is the check component, the step which requires the most developer intervention, in the form of a checklist.
How VIBE✓ is Implemented Into Mozilla.ai’s cq
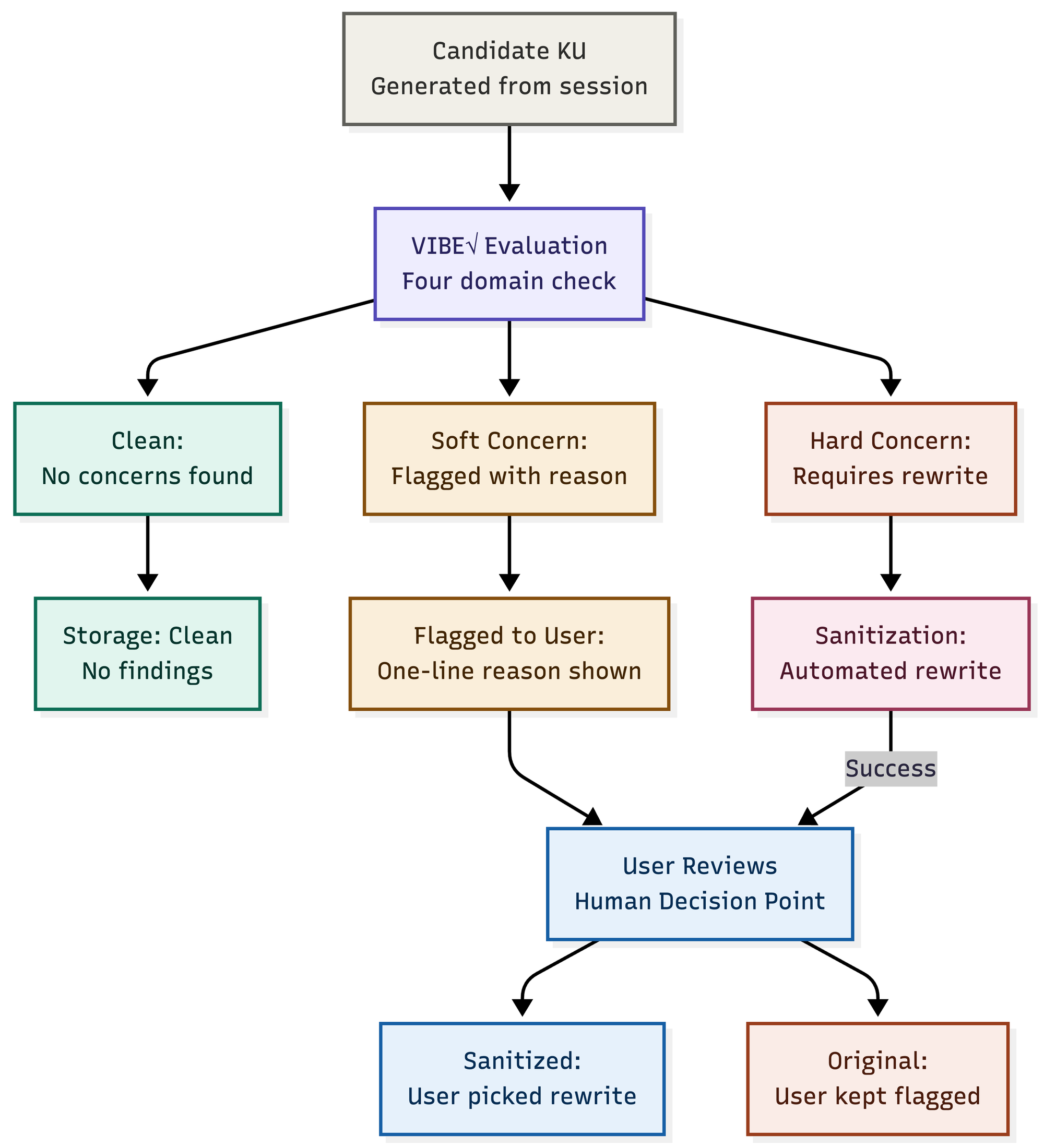
VIBE✓ is directly integrated into cq’s reflect and propose functionality, the cq knowledge unit pipeline, operating as an additional sanitization check for the user. When a user invokes /cq:reflect, the system generates candidate knowledge units based on the current coding session. Before these units surface for your review, VIBE✓ evaluates each one against its four accountability domains, and then classifies them as one of the following: clean, soft concern, or hard-finding.
Once this categorization is complete, the developer is prompted to review the findings, which is the most critical step in the VIBE✓.
- For soft concerns, a one line reason is given as to why the knowledge unit might be problematic.
- If a hard-finding is raised, a rewrite is also presented, giving the developer an option for graduation that has been sanitized.
The sanitization process is automated, but the approvals are done by human-in-the-loop. We are taking deliberate advantage of the friction inherent in the /cq:reflect functionality to ensure that unintentional breaches and sociotechnical blind spots from the skill are caught.
You can think of /cq:reflect as a batch mode for gaining coding session insights through an agent.
The Future of VIBE✓: How We Envision this in Practice
What VIBE✓ accomplishes is procedural accountability at the point of knowledge consolidation, catching a flaw before it becomes encoded into system memory, through a four-domain filter and human ratification. In the future, this framework’s utility could scale beyond our cq implementation to a benchmark standard across AI development pipelines, providing visibility for what infrastructure obscures.
While we designed this framework with the idea of automation bias in mind, we are also aware that checklists alone cannot entirely eliminate this type of human behavior in the face of automation; and it similarly doesn’t eliminate the risk that a developer under the pressure of a deadline will approve knowledge units without scrutiny. The intentional friction that this framework introduces relies on the developers having the material conditions to exercise judgement: time, realistic shipping schedules, and institutional support for saying “no” to a sanitized rewrite that still encodes harm.
We intend for this framework to exist as infrastructure, to be paired with industry transformation, pushing for continued use of judgment throughout the shipping process. And, although we find VIBE✓ as a promising way to combat automation bias and sanitization of KUs, it is not a replacement for backend guardrail pipelines. As cq develops, we hope to continue hardening the system to make it as safe and usable as possible.
Try out cq today!
If you found this post interesting and want to learn more about cq, we recommend reading our OSS release blog post and GitHub repo. Make sure to install cq into your coding agents as well!