
The Challenge of Choosing the Right LLM
Imagine you could effortlessly navigate the universe of LLMs, always knowing which one is the perfect fit for your specific query. Today, this is a very difficult challenge. So, how do you efficiently manage and use LLMs for various tasks? This is where LLM Routing emerges as a crucial strategy.



Imagine you could effortlessly navigate the ever-expanding universe of Large Language Models (LLMs), always knowing which one is the perfect fit for your specific query. The reality of today's LLM landscape makes this a very difficult challenge. On one hand, there is rapid growth in the number and diversity of open-weight LLMs on places like Hugging Face. Meanwhile, behind closed doors, there is an arms race among AI companies to roll out the biggest, most powerful models via APIs.
So, how do you efficiently manage, compare, and use the growing number of LLMs for various downstream tasks? This is where LLM Routing emerges as a crucial strategy: By dynamically selecting the most appropriate model based on factors like, e.g., query complexity, LLM routing aims to optimize things like cost and resource consumption while ensuring high-quality responses.
This post dives into different approaches to tackling this LLM selection and optimization challenge, but first, let’s concretely define the problem.
Problem Formulation
Before diving deeper into the different ways of herding LLMs, let's nail down exactly what puzzle we're trying to solve. Imagine you’ve got a whole toolbox full of different LLMs. Each one is a tool — a function that takes a question and provides an answer. Now, some of these tools are really good at giving high-quality answers, but they also come with a hefty price tag. Others tend to give answers that are less “polished,” but will cost you less.
The core task of an LLM router is to figure out how to intelligently choose a model from the collection of all LLMs, for each incoming user question. And when we say intelligently, we mean balancing different trade-offs, like getting a great answer without breaking the bank, or getting a good answer without hogging all the resources.
How does this work?
The field of LLM routing largely splits into two schools of thought: Should we decide which LLM to choose before it generates a response, or after?
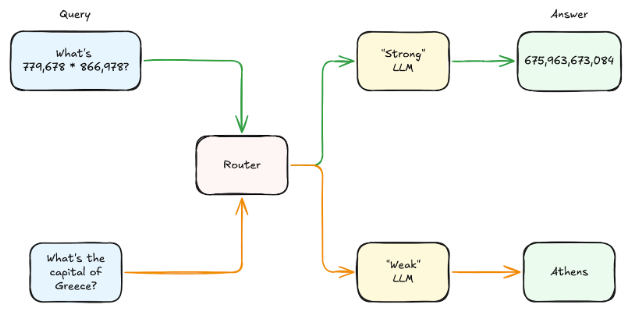
The “before” team, known as pre-generation or predictive routing, is all about making a smart choice upfront, kind of like picking the right tool for the job before you start. This usually means only one LLM is queried, which is great for keeping costs and latency down. Techniques like Hybrid LLM and RouteLLM exemplify this by training a router to send simpler queries to a smaller, thus cheaper model, while reserving the heavy lifting for larger, more expensive models, using either synthetic or human preference data as their guide. On the other hand, approaches like MetaLLM use a contextual multi-armed bandit model, a form of reinforcement learning, to balance performance and cost by learning to select the least expensive LLM with a high probability of providing a correct answer for a query. Meanwhile, EmbedLLM focuses on learning compact vector representations (embeddings) of LLMs, aiming to capture important features of the models. These model embeddings can strengthen the performance of several downstream tasks, one of which is model routing. This is achieved by predicting how a model will handle a specific query without performing inference.
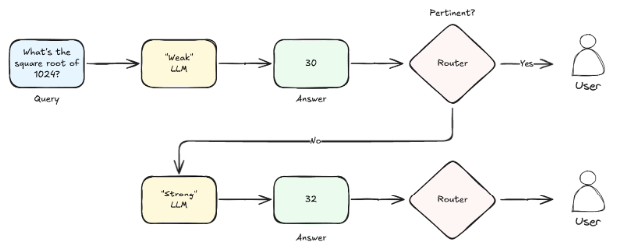
On the other side of the coin is post-generation routing, where the strategy is to let one or more LLMs actually generate responses before a final decision is made. This approach can sometimes produce top-notch outputs, but it might also mean digging a bit deeper into your wallet or practicing a little patience, as several LLMs could be used to generate a single response. The LLM cascade strategy, notably used by FrugalGPT, is a good example of this approach. It sends a query to a list of LLMs one by one, starting with the cheaper options. The first model to provide an answer deemed good enough gets selected, and the process concludes. For FrugalGPT, "good enough" is determined by a scoring function, specifically a DistilBERT regression model, which generates a reliability score given a query and an answer. It returns the generation if the score is higher than a certain threshold, and queries the next service otherwise. Consequently, for some queries, it’s like a few different models get a chance to shine before the right answer is found, unlike the typical single-call pre-generation methods.
Conclusion
So, what should you use? Pre-generation strategies are prioritizing efficiency and saving money by making an informed choice upfront, usually sticking to a single LLM call. Then there are the post-generation methods, which often aim for premium quality by letting a few LLMs demonstrate what they can do before picking a winner, even if it means you’ll have to pay more and wait longer.
Ultimately, the ideal approach depends on your specific priorities, balancing cost, quality, and performance to find the right fit for your unique needs.



