
The Misunderstood Small Model Market: A Look Beyond OpenRouter's Data
The State of AI report from OpenRouter and a16z offers valuable insight into API-based model usage. But many small models run locally on CPUs and consumer GPUs, outside managed services. This finding, however, warrants critical examination.



The recent State of AI report by OpenRouter and Andreessen Horowitz (a16z) offers compelling insights into the growing adoption of open-weight LLMs. It categorizes models by size:
- Small: Models with fewer than 15 billion parameters.
- Medium: Models with 15 billion to 70 billion parameters.
- Large: Models with 70 billion or more parameters.
While the data clearly shows that the medium-size model market has successfully found its "market-model fit," experiencing a significant surge in usage, the report simultaneously notes an overall decline in the usage share of small models. This finding, however, warrants critical examination. Models smaller than 15 billion parameters are specifically designed to run efficiently on commodity hardware, such as consumer-grade GPUs or even modern CPUs, often leveraging optimized inference servers like llama.cpp, llamafile, ollama, and LM Studio.
Consequently, the OpenRouter dataset, which is limited to models offered via its managed API service, does not capture the vast landscape of local, self-hosted deployments. This systemic data limitation means that the usage patterns of the most cost-efficient, smallest open-weight models are simply invisible to the report.
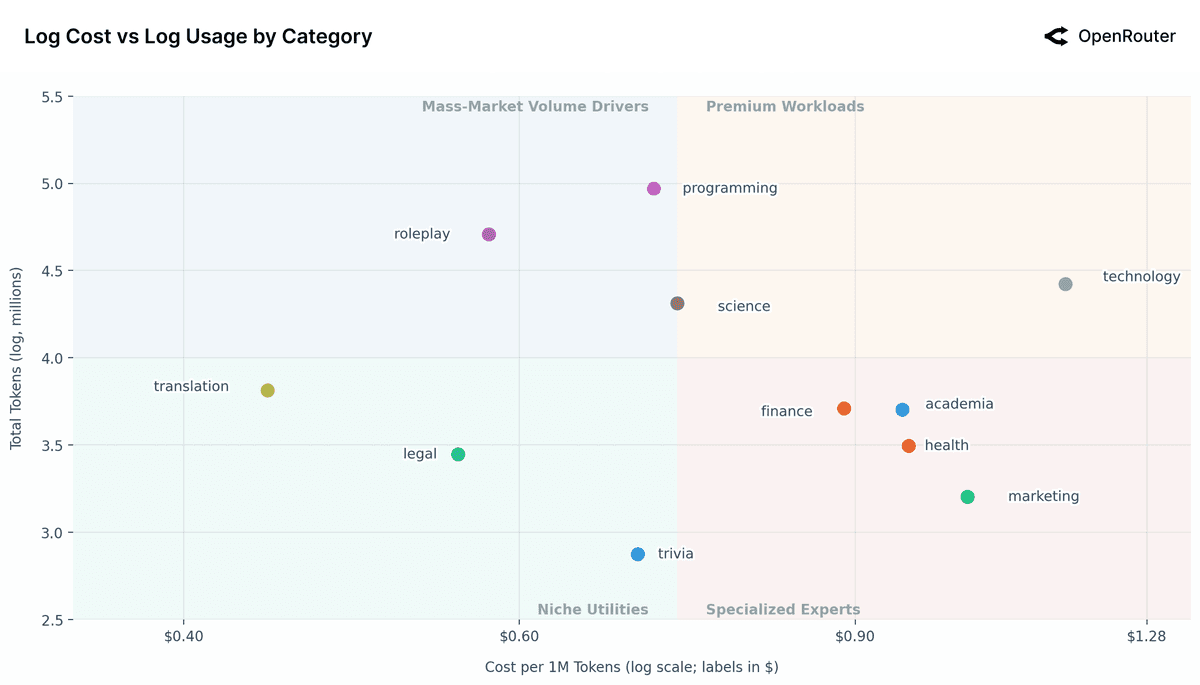
It's highly probable that small models are widely deployed for highly specific utility-focused use cases, such as on-device translation, focused summarization, and local data processing, often in niche, private deployments. This corresponds to the bottom-left quadrant that is formulated in the “Log Cost vs Log Usage by Category” figure.
any-llm-platform, in conjunction with any-llm, offers visibility into this decentralized usage. This provides crucial insight into the world of small, open-weight models, just as it does for models served behind APIs (e.g., OpenAI, Anthropic).
Anyone using any-llm locally to create completion requests to inference servers like llamafile, Ollama or LM Studio can benefit from the centralized view of usage events that any-llm-platform offers, even when the entire inference procedure takes place on their laptop.



