
What is an LLM control plane?
Runaway agents? Provider outages? Discover why your AI stack needs an LLM control plane, not just a gateway, to handle production routing, budgets, and privacy.


An agent stuck in a reasoning loop doesn't crash. It just quietly burns through your monthly budget until someone notices the bill. A week later, a provider has an outage and your app goes down with it, because there was no fallback to catch it. Your security team asks what data your model sent to which provider last week, and the honest answer is you don't really know. Costs are creeping up and you can't say which app, which model, or which team is responsible.
It's sadly the default state of running LLMs in production. The reason it keeps happening is that most teams are working with "AI" in their own way. Some build routing logic by bolting it into the application layer. Some track tokens on the side as an afterthought. Every team rebuilds the same plumbing from scratch, badly, because there's no standard protocol for handling it.
We solved this everywhere else in infrastructure. API gateways, service meshes, Kubernetes control planes. There's just never been an equivalent for LLM traffic. This is where an LLM control plane comes in.
LLM Gateway vs. Control Plane
You've probably heard some combination of these: {AI, LLM} × {gateway, router, proxy}, plus "control plane." The terms get used interchangeably, but the line between them is the line between pretty demos and production-hardened software.
A gateway handles the mechanical layer: it routes requests, manages API keys, enforces rate limits. Your app talks to one endpoint instead of five. For an early-stage project, that's often good enough.
A control plane handles the decisions, not just the plumbing. It's the difference between "did this request go through" and "should this request go through at all." It enforces budget limits before a request runs instead of tallying them up after, applies one policy across every app and model instead of ten copy-pasted versions, and fails over when a provider dies.
Most teams outgrow a gateway fast. You add a proxy, get routing and logging, and then as usage increases the real questions land: how do you stop one runaway agent from blowing up your budget? How do you track spend across multiple users and sessions, not just per call? A gateway wasn't built for that, a control plane is.
| Feature | LLM Gateway (the plumbing) | LLM Control Plane (the brain) |
|---|---|---|
| Primary Focus | Execution and connectivity | Policy and decision-making |
| Routing | Static or simple fallback | Dynamic, policy-driven routing |
| Budgets | Post-call token tallying | Pre-request limit enforcement |
| Scope | Point-to-point for an app | Global policy across all apps & models |
The three planes of LLM Infrastructure
This is not a new problem. Networking (and others) solved a version of it decades ago.
The trick was to stop building one monolithic system and split it into planes. The data plane moves the traffic. The control plane decides where it goes and what's allowed. The management plane is where humans configure and watch the whole thing. That same split maps cleanly onto LLM infrastructure. If you've worked with Kubernetes, you've already seen this: the control plane is the part that decides and enforces, while the workloads just run.
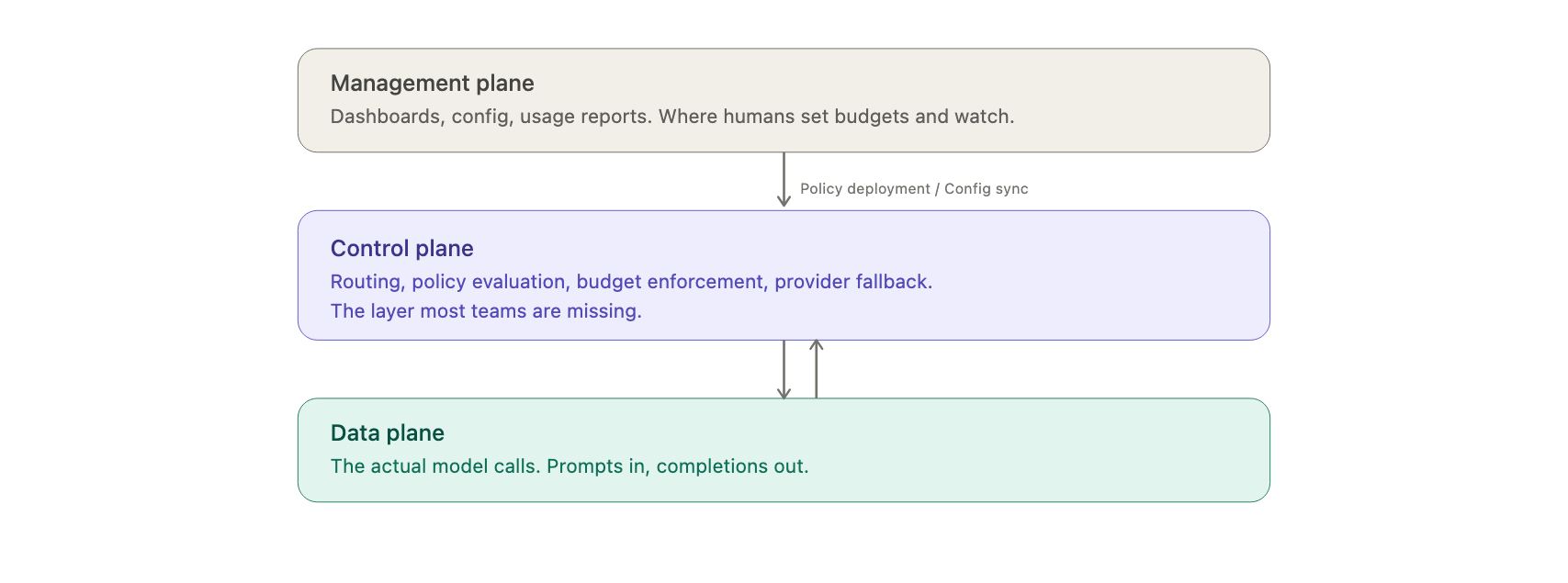
Today most LLM infrastructure covers the data plane and a thin slice of the management plane. The LLM control plane is the gap, the layer everyone ends up hand-building, which is exactly the layer that should be standard infrastructure.
What a control plane actually needs to do
The term gets used loosely, so I’m setting a concrete bar. A real LLM control plane should handle most of this:
- Hard budget limits that block new requests the moment a threshold is crossed, preventing a runaway agent from spending a penny over your configured limit.
- Spend tracked across users and sessions. Per-call numbers are easy; "what did this team cost last month" is the one that actually matters.
- Policy-driven routing across providers, with automatic failover when one goes down.
- One place to apply guardrails on prompts and responses, instead of reimplementing the same checks in every service.
- A full audit trail. Every request, response, and routing decision logged for when security or finance comes asking.
- Provider credentials in one vault, not scattered across a dozen env files.
It's the plumbing every team has to rebuild for itself. The point of a control plane is that you don't need to anymore.
Why where it runs matters
A control plane sits directly in the execution path of every prompt, completion, and credential. It's the most sensitive point in your AI stack, so where it runs isn't a minor detail.
With most tools you face a tradeoff: self-host a complex piece of infrastructure to guarantee privacy or hand your traffic to a SaaS provider where privacy is only as good as the contract. That's the tradeoff worth questioning. Owning the boundary and not having to run the infrastructure yourself shouldn't be mutually exclusive.
A Note from the Author
That tradeoff is the problem we're building Otari to remove. It's an open-source LLM control plane that handles routing, budgets, guardrails, and observability in one place. Self-host it when the data demands it, or use a managed deployment built so your keys, prompts, and responses stay yours either way. Pick your boundary, not the compromise.
Otari is still early. If you're scaling LLM infrastructure and want to stop hand-building your own plumbing, the Otari code and docs are a good place to start.



